By default database columns are case sensitive in PostgreSQL. For the most part this is fine, but there are cases where we want a column to ignore casing. In this brief post we’ll look at how to set up case insensitive columns with PostgreSQL in the context of a Phoenix application.
What we’ll build
For the purposes of demonstration we’ll build a simple Phoenix application which contains a Users table. The table will contain a user_name column that we want to be case insensitive. That is we want the user names i_am_bob and I_am_Bob to be considered as duplicate, not distinct.
Let’s get started!
Create the app
We’ll start from scratch with a new Phoenix application and add some simple scaffolding for the User functionality.
Terminal
mix phx.new so_insensitive
Choose Y when asked to fetch and install dependencies. Now we’ll change into the application directory and create the database.
Terminal
cd so_insensitive
mix ecto.create
Ok, our basic application is good to go, now let’s add some simple scaffolding.
Adding some scaffolding
So we won’t be adding an implementation that corresponds to a “real” user implementation, but just some simple scaffolding and fields for demonstration purposes.
Terminal
mix phx.gen.html Accounts User users user_name:string first_name:string last_name:string
As per the mix output, let’s update the routes…
/lib/so_insensitive_web/router.ex …line 16
scope "/", SoInsensitiveWeb do
pipe_through :browser
get "/", PageController, :index
resources "/users", UserController
endBefore running the migration, let’s update the migration and schema slightly.
We’ll start with the migration.
/priv/repo/migrations/timestamp_create_users.exs
defmodule SoInsensitive.Repo.Migrations.CreateUsers do
use Ecto.Migration
def change do
create table(:users) do
add :user_name, :string, null: false
add :first_name, :string, null: false
add :last_name, :string, null: false
timestamps()
end
create unique_index(:users, :user_name)
end
endWe’ve updated all the fields with null: false to indicate they are required. We’ve also added a unique index on the user_name. This enforces the uniqueness of the user_name field and also means look-ups based on the field will be more efficient.
Now for the schema.
/lib/so_insensitive/accounts/user.ex
defmodule SoInsensitive.Accounts.User do
use Ecto.Schema
import Ecto.Changeset
schema "users" do
field :first_name, :string
field :last_name, :string
field :user_name, :string
timestamps()
end
def changeset(user, attrs) do
user
|> cast(attrs, [:user_name, :first_name, :last_name])
|> validate_required([:user_name, :first_name, :last_name])
|> validate_length(:user_name, max: 20)
|> unique_constraint(:user_name)
|> validate_format(:user_name, ~r/^[a-zA-Z0-9_]*$/,
message: "Only letters, numbers and the `_` character are valid values.")
end
endWe’ve kept everything the same except for the changeset. We’ve added a number of validations to be applied against the user_name field. We limit the username to 20 characters, add a unique constraint, and specify that it can only contain letters, numbers and the underscore character. This is a pretty common set of restrictions that one might apply to a user name.
With all that out of the way we can run the migration.
Terminal
mix ecto.migrate
This completes our “application”, let’s have a quick look and see how our user_name column currently acts.
Terminal
mix phx.serverIf you navigate to http://localhost:4000/users you’ll see the users scaffolding we created. We can create two users with the same user name, just different casing.

If we attempt to create a third user with the same user name and casing we won’t be able to.
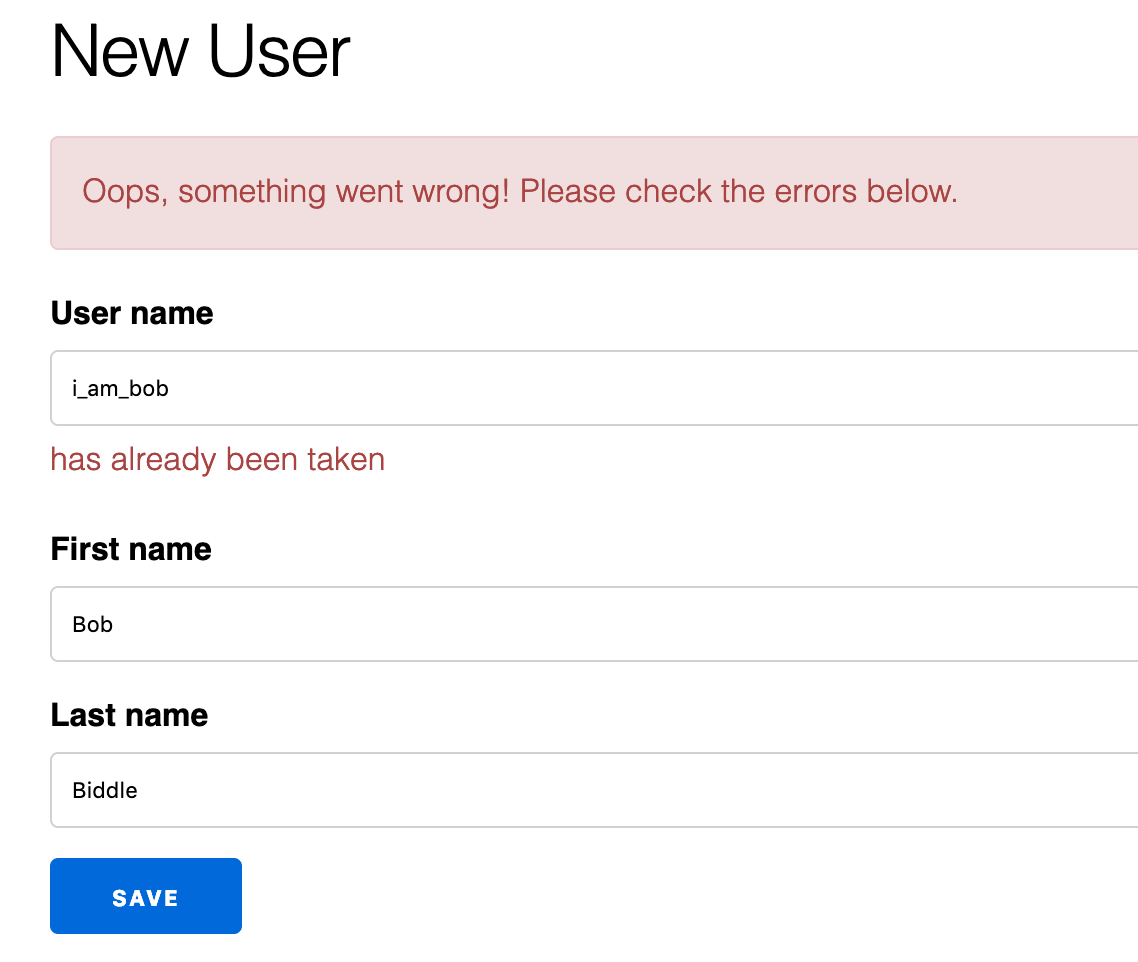
So our uniqueness is enforced… but it is a case sensitive uniqueness. Let’s look at how we can change this.
Making the user_name field case insensitive
The first thing we need to do is enable case insensitive columns in our PostgreSQL database. We can use a migration for this.
Terminal
mix ecto.gen.migration add_citext/priv/repo/migrations/timestamp_add_citext.exs
defmodule SoInsensitive.Repo.Migrations.AddCitext do
use Ecto.Migration
def change do
execute "CREATE EXTENSION citext", "DROP EXTENSION citext"
end
endAll this does is add the citext string type to our database. As you probably guessed, the ci stands for case insensitive. The citext type behaves pretty much exactly like the text character type, but is case insensitive.
Next we’ll need to create a migration to update the user_name field in the Users table.
Terminal
mix ecto.gen.migration modify_users_make_username_ci/priv/repo/migrations/timestamp_modify_users_make_username_ci.exs
defmodule SoInsensitive.Repo.Migrations.ModifyUsersMakeUsernameCi do
use Ecto.Migration
def change do
alter table(:users) do
modify :user_name, :citext, null: false
end
end
endSimple, we’ve updated the column type user_name to citext.
One complication is we have existing data in our database that violates our new column type (i.e. our i_am_bob and I_am_Bob users). If we already had an application in production we would have a minor complication on our hands. Since this is not the case, we’ll simply drop and re-create the database with ecto.reset.
Terminal
mix ecto.reset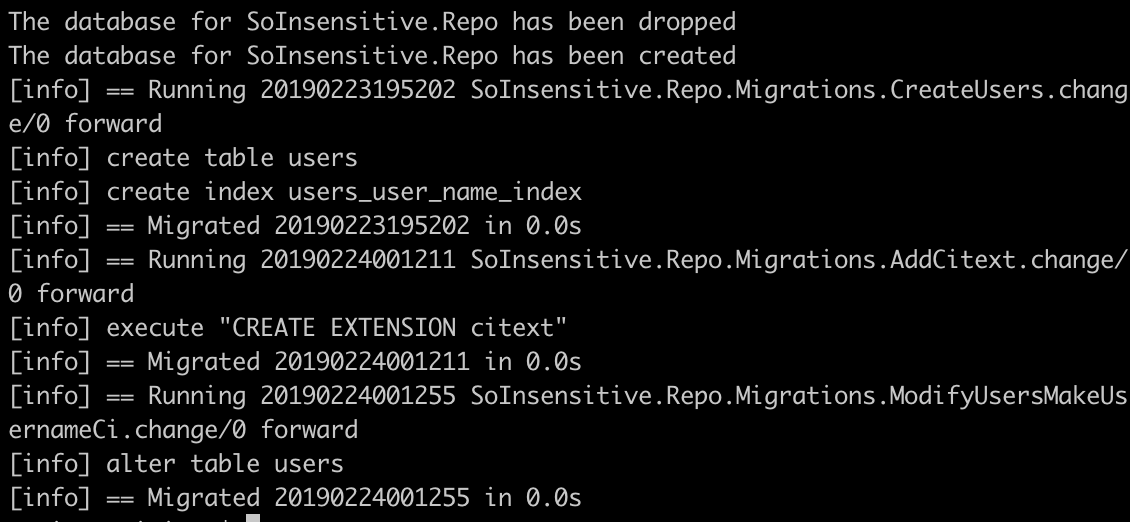
Now let’s fire things up and see what happens.
Terminal
mix phx.serverAfter re-creating our i_am_bob user, attempting to create I_am_Bob gives us our desired behaviour.
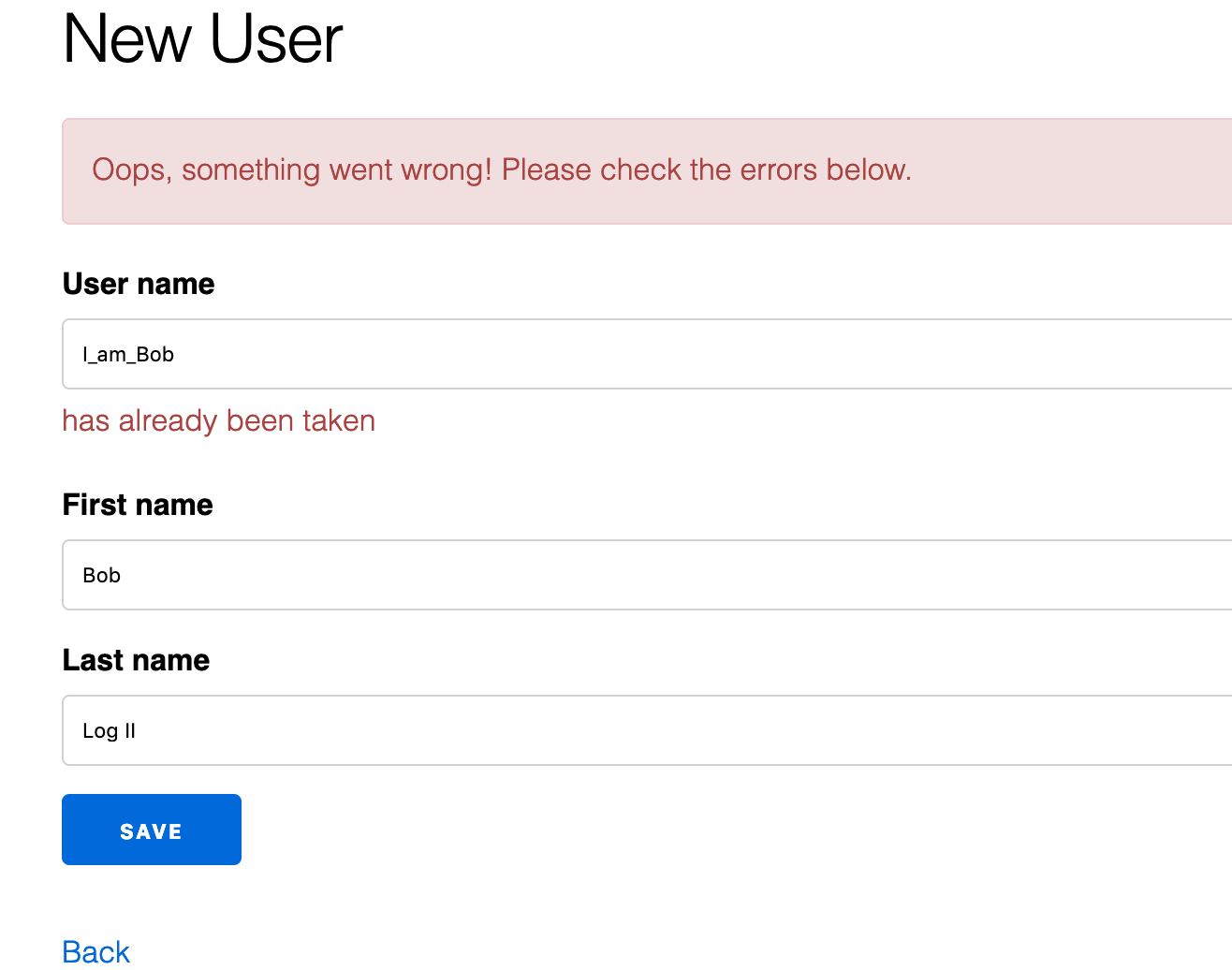
Fantastic!
Summary
There are some common situations where it is preferable to have case insensitive fields. Luckily this is pretty easy to set up with PostgreSQL and Phoenix. We simply need to enable the citext module in our PostgreSQL database and then indicate that as the column type for any desired fields in our schema file. Simple!
Thanks for reading and I hope you enjoyed the post!