Elixir is an interesting functional language based around Erlang. I’ve read the odd article about Elixir but only recently spent any significant time with it. I thought a series of posts around creating a Twitter scraper might be a good way to help me dive into the language… so here we are!
What we’ll build
This series of posts will concentrate on building an Elixir application that will allow us to scrap data from Twitter. Twitter has an API which would likely be the way to go if building a real application, but building a scraper is a good exercise and the approach we will take.
The motivation for the scraper
What’s the motivation for our scraper? After all we should have a reason for building something! The long term plan is to create a Phoenix application which displays images we’ve scraped from Twitter.
This is more aspirational than anything, we’ll see if we get that far or not. I’m claiming no promises that we’ll get any further than the scraper, but the basic idea is as below:
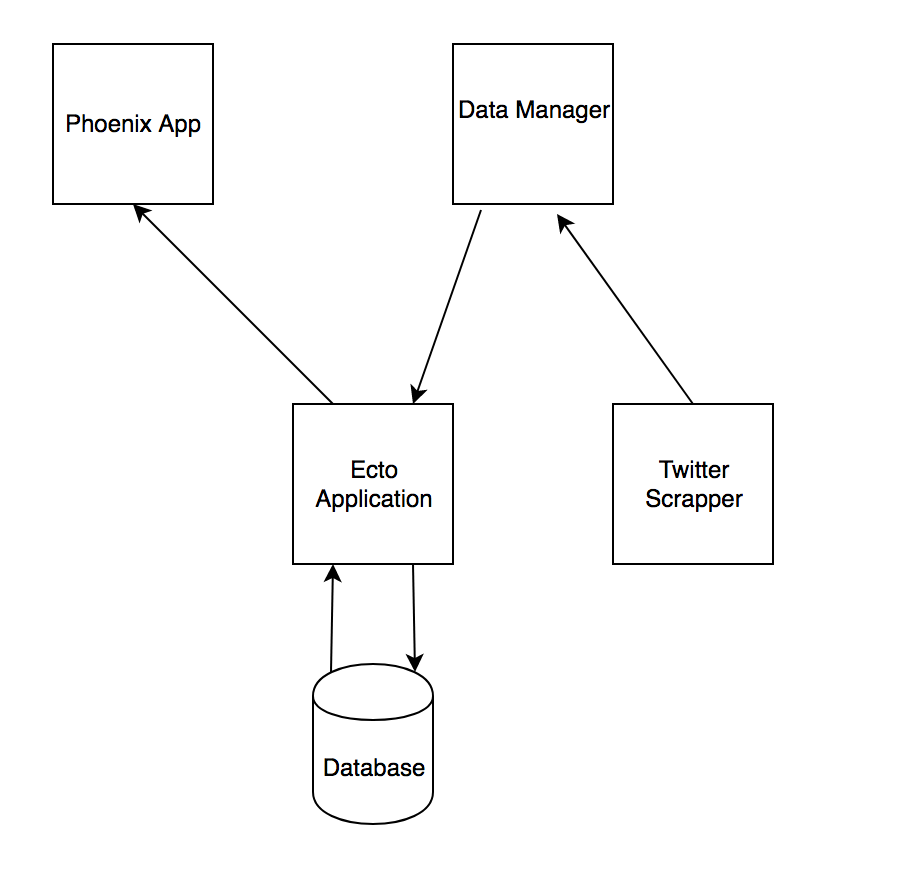
So the plan is we’ll have a data manager that will coordinate inserting our images into a database. A Phoenix application will pull and display images from the database. Again this is very much aspirational… most likely I’ll be stopping after the scraper is complete!
How to scrap data from Twitter
Twitter uses infinite scrolling which presents a bit of a challenge compared to a website that uses traditional paging; where we’d expect to be able to scrap successive pages via something like www.example.com/page2, www.example.com/page3 etc. Twitter displays 20 tweets per page, so each time a scroll event is triggered, another 20 tweets are loaded; the browser’s URL remains static however.
The following post is a good resource for determining how to scrap pages with infinite scrolling: https://www.diggernaut.com/blog/how-to-scrape-pages-infinite-scroll-extracting-data-from-instagram/ .
I used a similar approach to determine how to scrap successive Twitter pages. I won’t be going thru the details, but the approach we will take is as follows:
- Grab the first page directly from Twitter, i.e.
https://twitter.com/<user_handle> - Subsequent pages will be accessed via a JSON request.
The format of the main URL is straight-forward, i.e. https://twitter.com/<user_handle>.
The JSON format is a little more involved: https://twitter.com/i/profiles/show/<user_handle>/timeline/tweets?include_available_features=1&include_entities=1&max_position=43452345&reset_error_state=false.
The key to the JSON request is the max_position value. This is the id of the tweet within the current feed that immediately precedes the tweets we want to retrieve… confused? Hopefully an example will clear things up.
Let’s say we have the following tweets:
| tweet_id | tweet_text |
|---|---|
| 12345 | Tweet One |
| 22345 | Tweet Two |
| 33456 | Tweet Three |
| 42345 | Tweet Four |
Running the JSON request with a max_position value of 22345 would mean we’d retrieve all the tweets after Tweet Two, i.e.
| tweet_id | tweet_text |
|---|---|
| 33456 | Tweet Three |
| 42345 | Tweet Four |
If you want to view the JSON request in action, click the following link https://twitter.com/i/profiles/show/lolagil/timeline/tweets?include_available_features=1&include_entities=1&max_position=944630222644637696&reset_error_state=false… you’ll download a file which will contain 20 tweets.
Now that we know how to get data from Twitter we can start building our scraper. One thing to note is there seems to be some sort of limitation on the JSON requests. After ~800-900 tweets no more pages are returned regardless of whether there are more pages of tweets. This doesn’t seem like a time based limitation as running the JSON request hours later still yields no results. If anyone has an idea as to why this happens, let me know! I didn’t spend a ton of time trying to figure it out as 800 or so tweets per feed is going to be fine for our purposes.
Time for some code
So much talking… so little coding… let’s get going with some code already!
For the rest of this post, we’re going to set up our basic project structure and then write the code that will handle the creation of our HTML and JSON URLs. We’ll also figure out our public facing API.
Setting up the project structure
The first step is to create an Elixir project, so let’s open up a command prompt and get that out of the way.
Terminal
mix new twitter_feed
Terminal
cd twitter_feed
mix testIf everything goes well, you should see the following in your command window.
Next step is to set up our directory structure and get rid of the default test file as we’ll not be using it for our tests. Our directory structure will follow the common convention of having a single ex file in our root lib directory that contains our public facing API. We’ll place everything that isn’t meant to be accessed outside of our project in an enclosing directory within lib, i.e. lib/twitter_feed. We’ll also create a directory to house code that is specific to interacting with Twitter in lib/twitter_feed/twitter_api.
Let’s do it!
Terminal
rm test/twitter_feed_test.exs
mkdir -p lib/twitter_feed/twitter_apiWe’re going to want a similar directory structure for our tests, so let’s do that next.
Terminal
mkdir -p test/twitter_feed/twitter_apiAnd with that we have our basic directory structure in place, if you view your directory structure it should look as below.
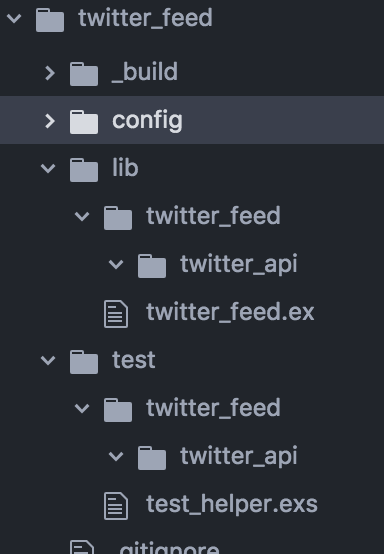
Building our URLs
A simple task to start with is to create some code to build our HTML and JSON URLs. We’ll place this in our twitter_api directory. The easiest way to validate our code will be to create some tests.
Building the HTML URL
We’ll start by defining a test and then follow up with the actual implementation.
We’ll need a new test file:
Terminal
touch test/twitter_feed/twitter_api/url_builder_test.exsAnd now for the content of the test.
/test/twitter_feed/twitter_api/url_builder_test.exs
defmodule TwitterFeed.TwitterApi.UrlBuilderTest do
use ExUnit.Case, async: true
alias TwitterFeed.TwitterApi.UrlBuilder
test "building the handle url" do
url = UrlBuilder.build_html_url("my_handle")
assert url == "https://twitter.com/my_handle"
end
endNothing special here, we’re aliasing our soon to be created UrlBuilder module, and the test itself is just checking that given a Twitter handle / username of my_handle the appropriate URL is built, i.e. https://twitter.com/my_handle.
Since we have no implementation we’ll get an error if we run the test.
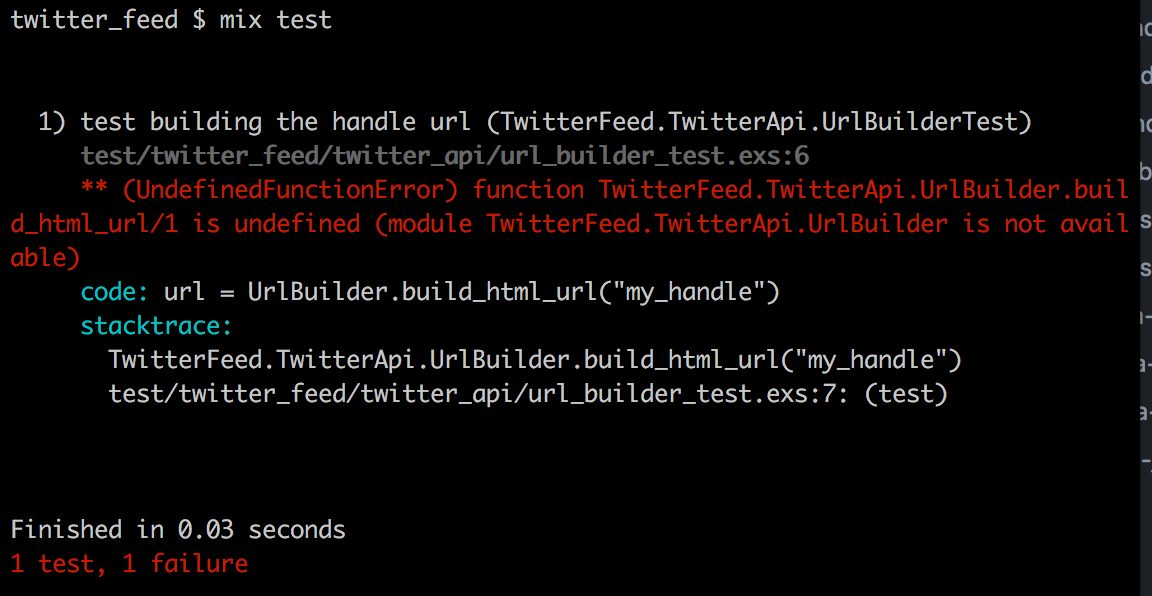
Let’s get this passing… first we need to create a file to hold the UrlBuilder module.
Terminal
touch lib/twitter_feed/twitter_api/url_builder.exOur implementation is very straight-forward, just some simple string interpolation.
/lib/twitter_feed/twitter_api/url_builder.ex
defmodule TwitterFeed.TwitterApi.UrlBuilder do
@base_url "https://twitter.com"
def build_html_url(handle) do
"#{@base_url}/#{handle}"
end
endWith that our test should now be passing.
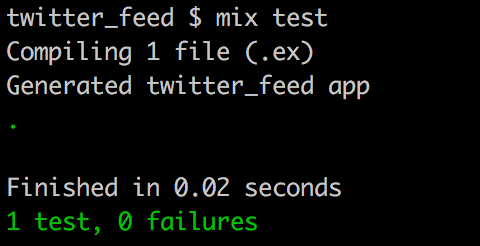
Building the JSON URL
The JSON URL is more complex but again we just need to build the appropriate string. Once again we need to insert the handle, but recall we also need to insert a tweet_id in the JSON URL as the value of max_position.
As before let’s start by creating a test.
/test/twitter_feed/twitter_api/url_builder_test.exs
defmodule TwitterFeed.TwitterApi.UrlBuilderTest do
use ExUnit.Case, async: true
alias TwitterFeed.TwitterApi.UrlBuilder
test "building the handle url" do
url = UrlBuilder.build_html_url("my_handle")
assert url == "https://twitter.com/my_handle"
end
test "building the json url" do
expected_url = "https://twitter.com/i/profiles/show/my_handle/timeline/tweets?include_available_features=1&include_entities=1&max_position=4&reset_error_state=false"
url = UrlBuilder.build_json_url("my_handle", 4)
assert url == expected_url
end
endOnce again we’re using my_handle as the Twitter handle / username, and for the tweet_id we’re using a value of 4.
Let’s update UrlBuilder to include an implementation for the JSON URL.
/lib/twitter_feed/twitter_api/url_builder.ex
defmodule TwitterFeed.TwitterApi.UrlBuilder do
@moduledoc false
@base_url "https://twitter.com"
@profile_path "i/profiles/show"
@timeline_path "timeline/tweets"
@static_parameter_1 "include_available_features=1"
@static_parameter_2 "include_entities=1"
@dynamic_parameter "max_position"
@static_parameter_3 "reset_error_state=false"
@path_seperator "/"
@query_seperator "&"
def build_html_url(handle) do
"#{@base_url}/#{handle}"
end
def build_json_url(handle, from_position) do
@base_url <> @path_seperator <>
@profile_path <> @path_seperator <>
handle <> @path_seperator <>
@timeline_path <> "?" <>
@static_parameter_1 <> @query_seperator <>
@static_parameter_2 <> @query_seperator <>
@dynamic_parameter <> "=#{from_position}" <> @query_seperator <>
@static_parameter_3
end
endIn order to try to make the code a little cleaner we’ve used a number of module attributes instead of a long string interpolation. Also notice we’ve added @moduledoc false to this module. The reason for this is this module is not going to be part of our public API so we don’t want documentation generated for it down the road if we decide to use ExDoc to create documentation for our project.
We should now have 2 passing tests:
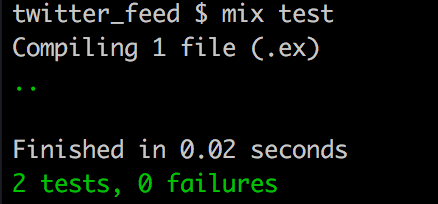
Wrapping up with a few miscellaneous tasks
To end off this post let’s handle a few miscellaneous tasks. We’ll come up with an initial public API for our scraper and also add test coverage via ExCoveralls.
Our public facing API
Our public facing API will go in twitter_feed.ex. This file currently has some pre-generated code in it as a result of running mix new. Let’s replace the generated code with our public API.
/lib/twitter_feed.ex
defmodule TwitterFeed do
defdelegate get_tweets(handle, start_after_tweet \\ 0),
to: TwitterFeed.Scraper, as: :scrape
endSo we’ve create a public interface for our project. We expect the outside world to call into our project by passing in a Twitter handle, and then optionally a tweet_id indicating where in the feed to start grabbing tweets. By default (indicated by the value following the double backslash) we’ll start from the top of the feed.
The code itself just delegates the call to our Scraper module.
For now let’s just throw up a skeleton of what our Scraper will look like.
Terminal
touch lib/twitter_feed/scraper.ex/lib/twitter_feed/scraper.ex
defmodule TwitterFeed.Scraper do
@moduledoc false
def scrape(_handle, _start_after_tweet) do
:ok
end
endSo for now Scraper just ignores the passed in parameter (via the underscores) and returns an :ok atom.
We can now run our project via iex, let’s give it a try:
Terminal
iex -S mixOnce iex loads up we can call into our function.
Terminal
TwitterFeed.get_tweets("someHandle")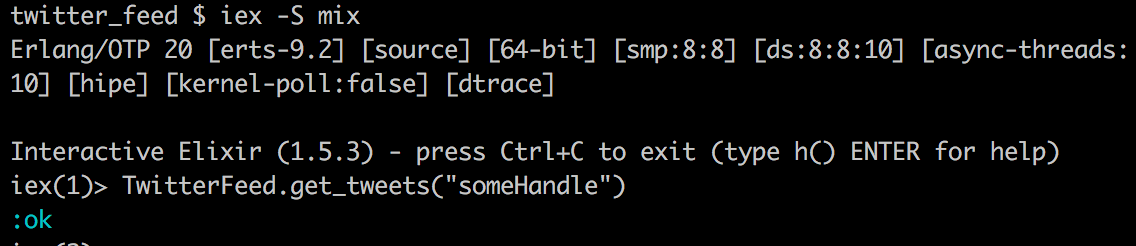
Sweet! press Ctrl+C twice to exit iex.
Adding code coverage
Finally let’s add code coverage to our project. This is pretty easy to do with Elixir. We just need to update our mix.exs file. Replace the current mix file with the below:
/mix.exs
defmodule TwitterFeed.Mixfile do
use Mix.Project
def project do
[
app: :twitter_feed,
version: "0.1.0",
elixir: "~> 1.5",
start_permanent: Mix.env == :prod,
deps: deps(),
test_coverage: [tool: ExCoveralls],
preferred_cli_env: [
"coveralls": :test,
"coveralls.detail": :test,
"coveralls.post": :test,
"coveralls.html": :test
]
]
end
def application do
[
extra_applications: [:logger]
]
end
defp deps do
[
{:excoveralls, "~> 0.8", only: :test}
]
end
endWe’ve added a new dependecy excoveralls, and updated the project section to include test_coverage and preferred_cli_env settings as per the ExCoveralls documentation.
Now we need to grab our new dependency:
Terminal
mix deps.getWith that we can now check our current code coverage:
Terminal
mix coveralls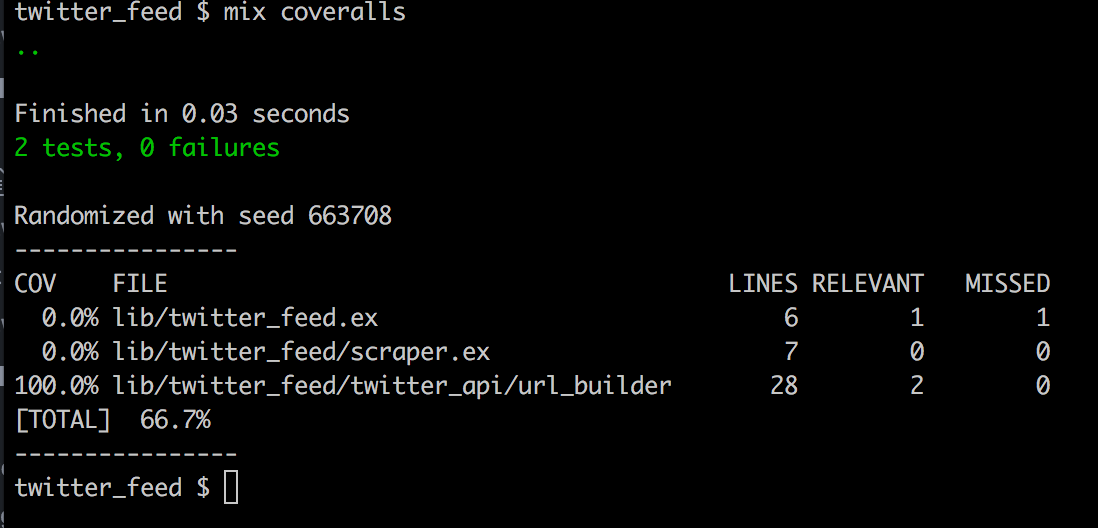
We’ve got 100% coverage for the UrlBuilder module, which is the only piece of functionality we’ve coded up, so we’re doing good!
Summary
That’s it for now, we didn’t write very much code in this post but we’ve got a decent start on our scraper. We figured out the format of the URLs required to grab our data from Twitter, and we’ve come up with our public facing API.
Next time we’ll figure out how to use the URLs from UrlBuilder to grab some data, and eventually we’ll be formatting and returning that data in a way that will be useful for external applications.
Thanks for reading and I hope you enjoyed the post!