In part 6 we improved the useability of our Scraper. In this post we’ll continue in this vein by adding some basic error handling and wrapping up a few loose ends.
I’d encourage you to follow along, but if you want to skip directly to the code, it’s available on GitHub at: https://github.com/riebeekn/elixir-twitter-scraper.
Getting started
If you followed along with part 6 just continue on with the code you created in part 6. If not and you’d rather jump right into part 7, you can use a clone of part 6 as a starting point.
Clone the Repo
If grabbing the code from GitHub instead of continuing along from part 6, the first step is to clone the repo.
Terminal
git clone -b part-06 https://github.com/riebeekn/elixir-twitter-scraper twitter_feed
cd twitter_feed
mix deps.getOK, you’ve either gotten the code from GitHub or are using the existing code you created in Part 6, let’s get to it!
Guarding against bad values in the start_after_tweet parameter
Our public API expects two parameters; a handle along with an optional start_after_tweet parameter, i.e.
/lib/twitter_feed.ex
We already manage an invalid handle by returning a 404 message from within scraper.ex, i.e.
/lib/twitter_feed/scraper.ex
What about invalid start_after_tweet values however? Let’s try a few and see what happens.
Terminal
iex -S mixTerminal
TwitterFeed.get_tweets("lolagil", 123)Here we’re passing in a tweet id that does not exist, and the result is:

So this looks OK, we simply end up with an empty Feed structure, which is likely a resonable result.
How about a non-numeric value:
Terminal
TwitterFeed.get_tweets("lolagil", "123")
Again we end up with an empty Feed structure, seems resonable.
Finally, how about a negative value?
Terminal
TwitterFeed.get_tweets("lolagil", -1)
Very nasty, we end up with a big dump of error text… I think we can do better than that, let’s add a quick test and improve on what we’re seeing.
The first step is to add a new Scraper test.
/test/twitter_feed/scraper_test.exs
defmodule TwitterFeed.ScraperTest do
use ExUnit.Case, async: true
alias TwitterFeed.{ Scraper }
test "scraping will fail when start_after_tweet < 0" do
{:error, reason} = Scraper.scrape("someTwitterHandle", -1)
assert reason =~ "invalid start_after_tweet argument, can't be < 0"
end
...
...From our test we can see that we’re expecting an :error atom and an appropriate message when a negative value is passed in.
The test will of course currently fail.
Terminal
mix test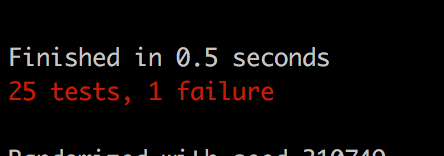
Let’s update our implementation to get the test to pass.
/lib/twitter_feed/scraper.ex
defmodule TwitterFeed.Scraper do
@moduledoc false
@twitter_api Application.get_env(:twitter_feed, :twitter_api)
alias TwitterFeed.Parser
def scrape(_handle, start_after_tweet) when start_after_tweet < 0 do
{:error, "invalid start_after_tweet argument, can't be < 0"}
end
...
...We’ve added a third scrape definition to specifically handle the case where start_after_tweet has a value of less than 0. Pretty simple, and our test is now passing!
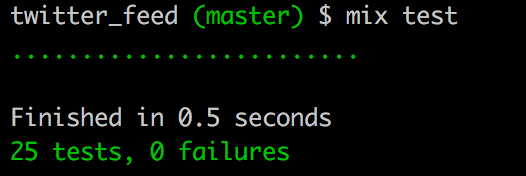
As expected, we now have a friendlier response in iex as well.
Terminal
iex -S mixTerminal
TwitterFeed.get_tweets("lolagil", -1)
An issue with 302 redirects
A strange issue I ran into about half-way through this series of posts was that calls to Twitter from HTTPoison started to result in 302 redirects. I think something temporarily changed with Twitter as requests from the Scraper were being redirected to the mobile version of Twitter.
For example, a request to https://twitter.com/lolagil would return a 302 response, with a redirect URL of https://mobile.twitter.com/lolagil, i.e.
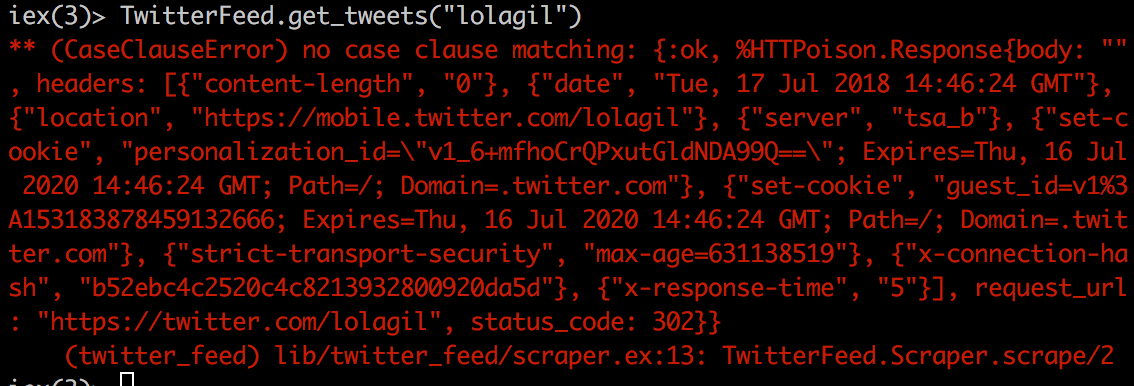
As can be seen above, we’re getting a 302 status_code value (i.e. a redirect) which we’re not currently matching on in our Scraper case statement. The location part of the response indicates the redirect is to the mobile version of Twitter.
It took me awhile to figure out what was going on… and the issue cleared itself up on it’s own after a few days. However, we can guard against this being a problem in the future. We can specify some headers in http_client.ex to indicate we are not on a mobile device, this should prevent any future problems. In case it doesn’t we should also add a new status code clause in scraper.ex to check for a 302 status.
Preventing 302 redirects to the mobile version of Twitter
Let’s start out by updating http_client.ex.
/lib/twitter_feed/twitter_api/http_client.ex
defmodule TwitterFeed.TwitterApi.HttpClient do
@moduledoc false
@behaviour TwitterFeed.TwitterApi.Api
alias TwitterFeed.TwitterApi.UrlBuilder
def get_home_page(handle) do
UrlBuilder.build_html_url(handle)
|> HTTPoison.get(get_headers())
end
def get_tweets(handle, last_tweet_retrieved) do
UrlBuilder.build_json_url(handle, last_tweet_retrieved)
|> HTTPoison.get(get_headers())
end
defp get_headers do
[
{
"user-agent",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
}
]
end
endWe’ve added a new private function get_headers which we pass into HTTPoison as a second parameter. The second parameter to HTTPoison.get is an optional header value which we were not previously populating. With the user-agent string we’re now passing in, this should indicate to Twitter that we are not on a mobile device and thus we should not be redirected.
If you want to see the 302 redirect for yourself, you can replace the user-agent string with Mozilla/5.0 (Linux; <Android Version>; <Build Tag etc.>) AppleWebKit/<WebKit Rev> (KHTML, like Gecko) Chrome/<Chrome Rev> Mobile Safari/<WebKit Rev>. If you recompile and run the Scraper with this string set as the header you’ll see the 302 redirect response being returned.
Handling 302 redirects
With our user-agent string set we don’t expect to run into any future 302 redirects but let’s update scraper.ex anyway just in case.
/lib/twitter_feed/scraper.ex
defmodule TwitterFeed.Scraper do
@moduledoc false
@twitter_api Application.get_env(:twitter_feed, :twitter_api)
alias TwitterFeed.Parser
def scrape(_handle, start_after_tweet) when start_after_tweet < 0 do
{:error, "invalid start_after_tweet argument, can't be < 0"}
end
def scrape(handle, 0) do
case @twitter_api.get_home_page(handle) do
{:ok, %{status_code: 200, body: body}} ->
body
|> Parser.parse_tweets(:html)
{:ok, %{status_code: 302, headers: headers}} ->
headers
|> return_302()
{:ok, %{status_code: 404}} ->
return_404()
end
end
def scrape(handle, start_after_tweet) when start_after_tweet > 0 do
case @twitter_api.get_tweets(handle, start_after_tweet) do
{:ok, %{status_code: 200, body: body}} ->
body
|> Parser.parse_tweets(:json)
{:ok, %{status_code: 302, headers: headers}} ->
headers
|> return_302()
{:ok, %{status_code: 404}} ->
return_404()
end
end
defp return_302(headers) do
header_map = Enum.into headers, %{}
url = header_map["location"]
{:redirect, "302 redirect received, redirect address: #{url}"}
end
defp return_404 do
{:error, "404 error, that handle does not exist"}
end
endWe’ve added a new private function to format a 302 response (defp return_302) along with case statements which will handle a status code of 302 from calls to @twitter_api.get_tweets or @twitter_api.get_home_page.
With this in place if we hit a 302 we’ll see something like:

Wrapping up
So this pretty much wraps up our Twitter scraper! Just a few final touches…
Code coverage
Let’s have a quick look at our code coverage.
Terminal
mix coveralls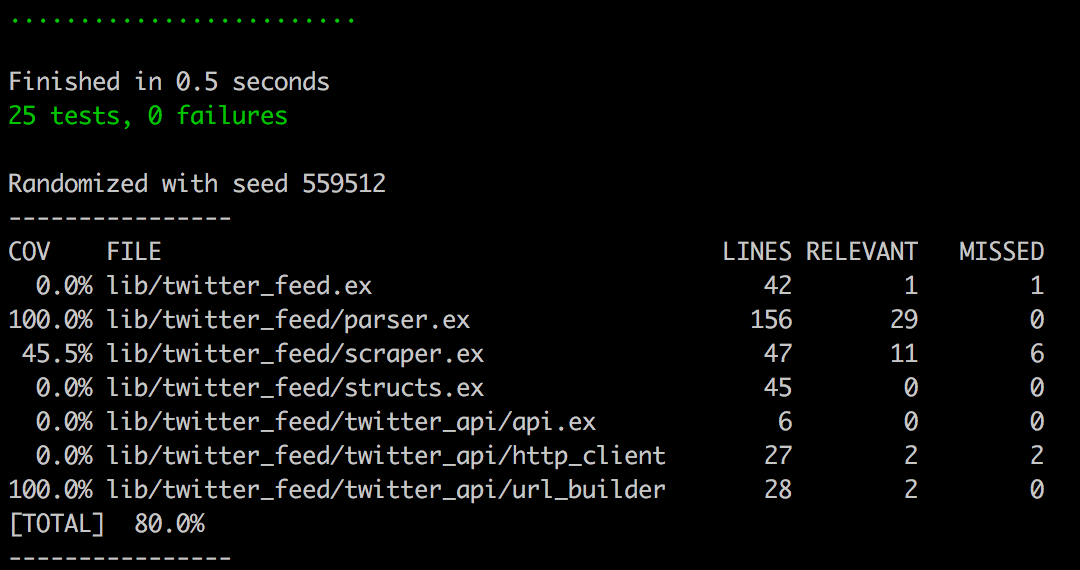
Not too bad, although with code coverage there always is room for improvement I suppose!
Documentation
We should also update our documentation, speaking of which we’ve forgotten to add documentation to our public API! So let’s do that.
/lib/twitter_feed.ex
defmodule TwitterFeed do
@moduledoc """
Provides an API to retrieve Tweets from a Twitter feed.
Contains a single method "get_tweets".
"""
@doc """
Retrieves the tweets posted to a paticular twitter feed.
## Parameters
- handle: a string representing the twitter handle to retrieve tweets from.
- start_after_tweet: an optional integer parameter that defaults to 0.
When 0 will retrieve tweets starting from the most
recently posted tweet. When populated with a
tweet id, will retrieve tweets starting from the first tweet posted
after the passed in tweet id.
## Returns
- {:error, reason} - on an invalid request (i.e. a handle that does not exist).
- {:ok, %TwitterFeed.Feed} - on a valid request.
## Examples
TwitterFeed.get_tweets("AGOtoronto")
{:ok, %TwitterFeed.Feed{last_tweet_retrieved: 966417486722863104,
more_tweets_exist: true,
tweets: [...]}
To then get the 2nd page of results use the
start_after_tweet value from the 1st request:
TwitterFeed.get_tweets("AGOtoronto", 966417486722863104)
{:ok, %TwitterFeed.Feed{last_tweet_retrieved: 965316001540788224,
more_tweets_exist: true,
tweets: [...]}
"""
defdelegate get_tweets(handle, start_after_tweet \\ 0),
to: TwitterFeed.Scraper, as: :scrape
endWe’ve kept the code as is, but added some fairly detailed comments. This seems appropriate considering this is our public facing API that we expect people to interact with.
Let’s generate the docs!
Terminal
mix docs
Opening the docs we see we’ve got some pretty decent information available for people who may want to use our Scraper.
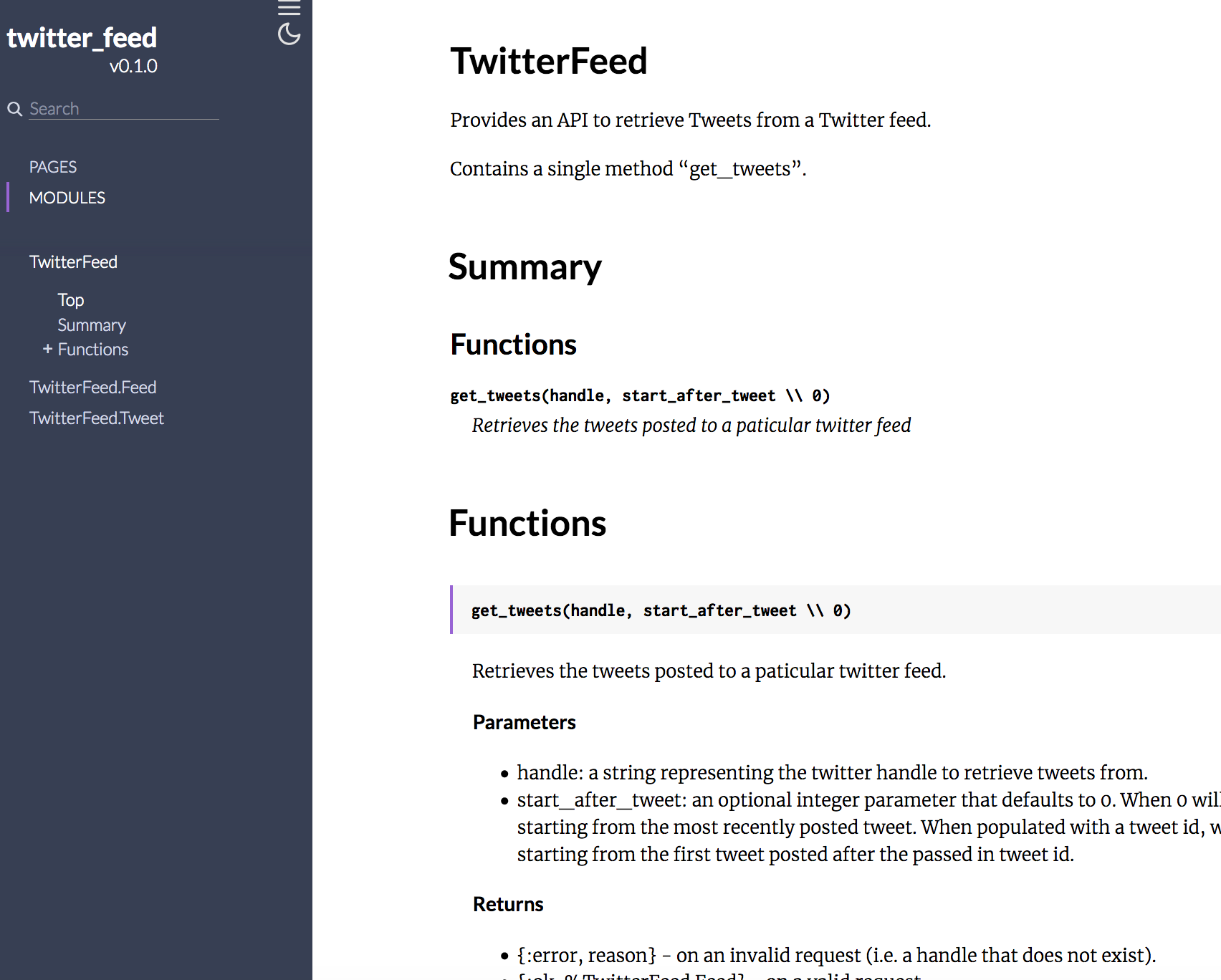
Summary
And with that we are done with our Scraper!
Thanks for reading and I hope you enjoyed this series of posts. In the future I may throw up a few quick posts demonstrating how the Scraper application could be used by other Elixir applications, but for now we’re done and dusted!