Seeding is a common data population technique when running an application during development, or for initializing test data. Phoenix already has us covered when it comes to seeding data, via the seeds.exs file generated when a new Phoenix project is created. This single file works great when dealing with relatively little data. Things can quickly get out of hand as the number of tables and data grows however. In this short post we’ll look at one option for splitting out seed data into multiple files.
Start with the default file
It makes sense to initially start things off with just the default seed file. When starting a project, we’re typically not dealing with a lot of data or tables, so the default file should serve us well.
Say we currently have two tables we’re dealing with, warehouses and products. An example file might look something like…
/my_app/priv/repo/seeds.exs
alias MyApp.Products.{Product, Warehouse}
alias MyApp.Repo
# add a couple of default warehouses
salt_lake =
%Warehouse{}
|> Warehouse.changeset(%{
external_id: "salt_lake_wh_1",
...
})
|> Repo.insert!()
}
portland =
%Warehouse{}
|> Warehouse.changeset(%{
external_id: "portland_wh_1",
...
})
|> Repo.insert!()
}
# add some products
...
...So this works fine. As our application grows however, we’re going to have more tables, and we’re going to want to split up the seed data so it stays manageable.
What to avoid
The way I often dealt with splitting up seed data in the past was to create a lib\seeds directory.
I’d then call out to the modules in this directory from seeds.exs, i.e. something like…
/my_app/priv/repo/seeds.exs
alias MyApp.Seeds.{
Distributors,
Products,
Roles,
Stores,
User,
Warehouses
}
# create 2 roles
admin_role = Roles.insert("admin")
emp_role = Roles.insert("employee")
# insert a bunch of users, with admin / emp roles
Users.insert_users(admin_role, emp_role)
...
...The problem with this approach is the seed modules are going to be included as part of the application code, and this is probably not desirable.
So what can we do? We can take a very similar approach, but just keep everything within the priv directory.
Keeping everything within the priv directory
Instead of throwing our seeds in the lib directory we’ll create our files within a seeds directory in priv/repo:
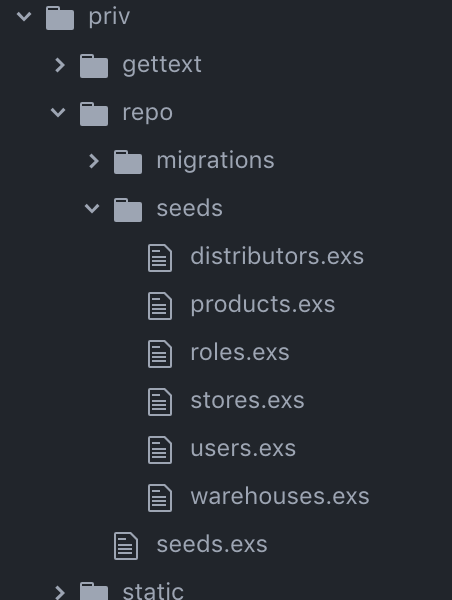
Now in the main seeds.exs file we can just require the files from priv/repo/seeds/.
/priv/repo/seeds.exs
########################################
# ROLES
########################################
Code.require_file("seeds/roles.exs", __DIR__)
########################################
# USERS
########################################
Code.require_file("seeds/users.exs", __DIR__)
########################################
# PRODUCTS
########################################
Code.require_file("seeds/products.exs", __DIR__)
########################################
# WAREHOUSES
########################################
Code.require_file("seeds/warehouses.exs", __DIR__)
########################################
# DISTRIBUTORS
########################################
Code.require_file("seeds/distributors.exs", __DIR__)The individual files, will look something like:
/priv/repo/seeds/roles.exs
########################################
# ROLES - create 3 custom roles
########################################
import Ecto.Query
alias MyApp.Accounts.Role
alias MyApp.Repo
%Role{
name: "admin",
...
}
|> Repo.insert()
%Role{
name: "employee",
...
}
|> Repo.insert()
%Role{
name: "sales_agent",
...
}
|> Repo.insert()This allows us to keep things organized but keeps the seeds out of our application code.
One drawback of splitting out seeds into multiple files is we’ll need to perform some extra querying. For instance when users are created in users.exs, we’re probably going to require the roles we created in seeds/roles.exs. So unlike where everything is in one file, we’ll have to query for these roles in users.exs. I feel the advantages of having better organized and more maintainable seeds outweigh this minor inconvenience.
Summary
Hopefully this post provides you with a few ideas for organizing your seed data in such a way that as your application grows you’ll end up with a beautiful orchard instead of a mess of vines!
Thanks for reading and I hope you enjoyed the post!