In Part 2 we figured out how to retrieve data from Twitter, and also worked on setting up some of our test infrastructure. In this post we’ll look at how to consume and format the data we’re retrieving.
I’d encourage you to follow along, but if you want to skip directly to the code, it’s available on GitHub at: https://github.com/riebeekn/elixir-twitter-scraper.
Getting started
If you followed along with part 2 just continue on with the code you created in part 2. If not and you’d rather jump right into part 3, you can use a clone of part 2 as a starting point.
Clone the Repo
If grabbing the code from GitHub instead of continuing along from part 2, the first step is to clone the repo.
Terminal
git clone -b part-02 https://github.com/riebeekn/elixir-twitter-scraper twitter_feed
cd twitter_feed
mix deps.getOK, you’ve either gotten the code from GitHub or are using the existing code you created in Part 2, let’s get parsing!
Determining what we need to parse
One thing we haven’t really addressed yet is what our expected data that we pull from Twitter looks like. We’ll have a hard time figuring out how to parse the data if we don’t even know what it looks like!
Getting a sample of our data
The easiest way to determine the format of our data is to navigate to a Twitter page, and then view and save the HTML source. For grabbing some test data, I navigated to https://twitter.com/lolagil, viewed the source and saved the contents. Since this Twitter page has likely changed since I downloaded it, I would suggest you download the copy I’ve saved as per the instructions below. This way we’ll be working off the same sample.
First let’s create our new project directory.
Terminal
mkdir test/dataThen download the file.
Terminal
curl -L -O https://raw.githubusercontent.com/riebeekn/elixir-twitter-scraper/master/test/data/twitter.html
mv twitter.html test/dataPerfect we now have some sample data to work with.
Updating the Twitter mock
If you recall from part 2 we’re not returning particularly realistic data from our mock, i.e.
/test/mocks/twitter_api_mock.ex
Although we won’t be concentrating on the Scraper tests for a bit, this is a good time to update our mock so it’ll be ready to go in the future.
To create a more realistic mock, we’ll return the contents of our sample data file.
/test/mocks/twitter_api_mock.ex
defmodule TwitterFeed.Mocks.TwitterApiMock do
@behaviour TwitterFeed.TwitterApi.Api
def get_home_page(:non_existant_handle) do
{:ok, %{status_code: 404}}
end
def get_home_page(_handle) do
body =
Path.expand("#{File.cwd!}/test/data/twitter.html")
|> File.read!
{:ok, %{status_code: 200, body: body}}
end
endIn get_home_page we’re now reading our sample file and returning the contents of it via the body return value. This is exactly what happens with the real implemention; just that the data is retrieved from Twitter instead of a local file.
This change will cause our Scraper test to fail. For now just to get it passing, we’ll just check that the response contains a DOCTYPE tag.
/test/twitter_feed/scraper_test.exs
...
...
test "scraping on valid handle will return some body content" do
body = Scraper.scrape(:any_handle, 0)
assert body =~ "DOCTYPE"
end
endWith that, our tests should all be passing.
Terminal
mix test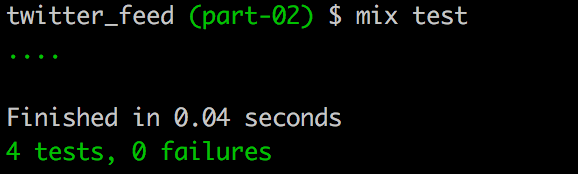
Parsing Tweets
Now that we have some sample data, let’s see if we can parse and format the data being returned. We’ll be looking to return a list of tweets when our public API is called.
Structuring our data
Let’s create a struct for the tweet data, we’ll place this in a general struct file as we’ll need some more structs down the road. Also note that we are including comments for our struct. Someone interacting with our application is likely going to appreciate knowing what our struct is returning, and this is something that we’d want ExDoc to generate documentation for.
Terminal
touch lib/twitter_feed/structs.ex/lib/twitter_feed/structs.ex
defmodule TwitterFeed.Tweet do
@moduledoc """
Struct representing a tweet.
## Fields
- handle_id: the handle of the current feed the tweet appears in.
- tweet_id: the id of the tweet.
- user_id: the user id associated with the tweet.
- user_name: the twitter handle associated with the tweet.
- display_name: the display name associated with the tweet.
- timestamp: the date / time the tweet was posted.
- text_summary: a summary of the tweet text.
- image_url: the url of any image contained in the tweet.
- retweet: true | false indicator of whether the tweet is a retweet.
"""
defstruct [
handle_id: "",
tweet_id: "",
user_id: "",
user_name: "",
display_name: "",
timestamp: "",
text_summary: "",
image_url: "",
retweet: false
]
endThere are a number of fields that we plan to return. Everything is pretty self-explanatory, maybe the only tricky aspect is the handle_id and user_id. The handle_id refers to the id of the current feed we are retrieving data from. For example, if we are looking at https://twitter.com/bobsFeed and Bob has an id of 1, and Bob has retweeted a tweet from https://twitter.com/sallysFeed and Sally has an id of 2… the handle_id would be 1; whereas the user_id would be 2, i.e. Sally’s id. This is because the user_id always refers to the user who created the original tweet. Similarily the display_name and user_name refers to the original author of a tweet, so in our example these fields would also refer to Sally.
Hopefully that is clear as mud! The next step is to create a Parser module that will be used to take the data we’re retrieving and populate our struct.
Terminal
touch lib/twitter_feed/parser.exLet’s create a simple function that takes in the HTML we retrieve and returns an empty list… in the future we’ll update this to return a list of TwitterFeed.Tweet structs.
/lib/twitter_feed/parser.ex
defmodule TwitterFeed.Parser do
@moduledoc false
def parse_tweets(html) do
[]
end
endLet’s update Scraper.scrape/3 to call into the Parser.
/lib/twitter_feed/scraper.ex
defmodule TwitterFeed.Scraper do
@moduledoc false
@twitter_api Application.get_env(:twitter_feed, :twitter_api)
alias TwitterFeed.Parser
def scrape(handle, _start_after_tweet) do
case @twitter_api.get_home_page(handle) do
{:ok, %{status_code: 200, body: body}} ->
body
|> Parser.parse_tweets()
{:ok, %{status_code: 404}} ->
return_404()
end
end
...
...We’ve added an alias for TwitterFeed.Parser, and updated the :ok clause of our case statement to call into our new Parser method.
Running in iex we should now get an empty list back.
Terminal
iex -S mixTerminal
TwitterFeed.get_tweets("lolagil")
Preparing to parse
So we’ve added a struct, created a Parser module, and updated the Scraper module to use the Parser… we’re finally ready to get to the meat of our task, the actual parsing of tweets! We’ll be using a Hex package called Floki to help with our HTML parsing. Let’s add it to our mix file.
/mix.exs
...
defp deps do
[
{:excoveralls, "~> 0.8", only: :test},
{:httpoison, "~> 1.0"},
{:floki, "~> 0.20.0"}
]
end
endAnd then update our project with our new dependency:
Terminal
mix deps.get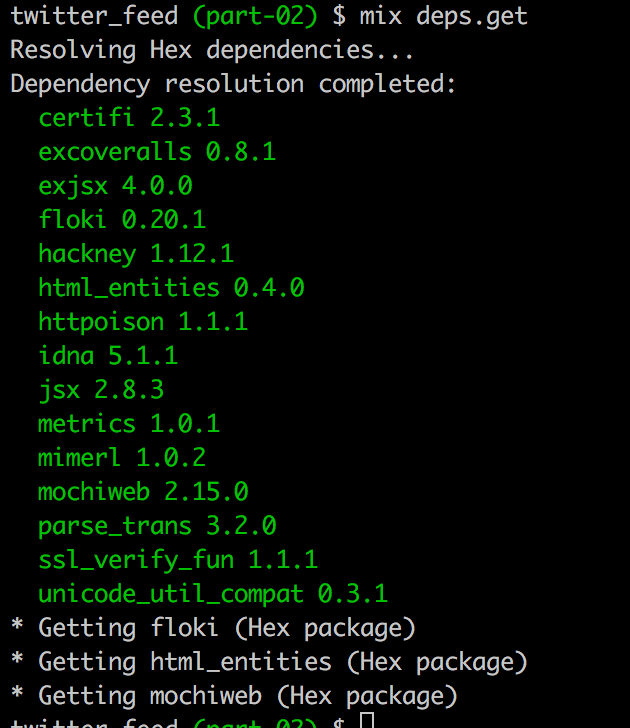
Now we need to update the Parser module to handle each Tweet we retrieve.
/lib/twitter_feed/parser.ex
defmodule TwitterFeed.Parser do
@moduledoc false
alias TwitterFeed.Tweet
def parse_tweets(html) do
tweet_html =
html
|> Floki.find(".tweet")
Enum.map(tweet_html, fn(x) -> parse_tweet(x) end)
end
##################### PRIVATE FUNCTIONS #####################
defp parse_tweet(tweet_html) do
%Tweet {}
end
endWe can see Floki in action here. If you look at our sample data file, you’ll notice that each Tweet is contained in a div with a class of .tweet. So we’re using Floki to find each tweet div and then passing each div to parse_tweet. For now the function just returns an empty Tweet struct.
Let’s see it in action:
Terminal
iex -S mixTerminal
TwitterFeed.get_tweets("lolagil")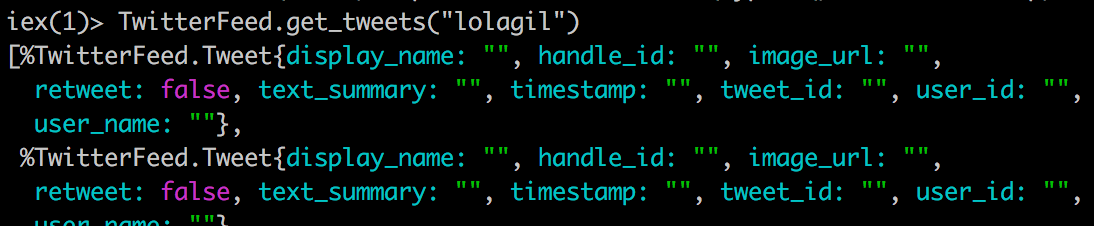
Perfect, for each tweet we’re returning an empty struct.
Note that our ScraperTest is now going to be failing. We could update it so that it passes; however we’re going to be changing the return value of our Parser.parse_tweets method a heck of a lot in the next while and it’s not going to be very efficient for us to keep updating the Scraper test. So let’s ignore it for now. How can we do that?
Pretty simple, first update test_helper.exs.
/test/test_helper.exs
ExUnit.start(exclude: [:skip])
Code.require_file("test/mocks/twitter_api_mock.ex")We’ve added an exclude parameter to ExUnit.start. This is going to allow us to skip tests by adding a @tag :skip directive as demonstrated below.
/test/twitter_feed/scraper_test.exs
...
...
@tag :skip
test "scraping on valid handle will return some body content" do
body = Scraper.scrape(:any_handle, 0)
assert body =~ "DOCTYPE"
end
endWith that, we can run our tests and avoid having a bunch of error output getting in our way.
Terminal
mix test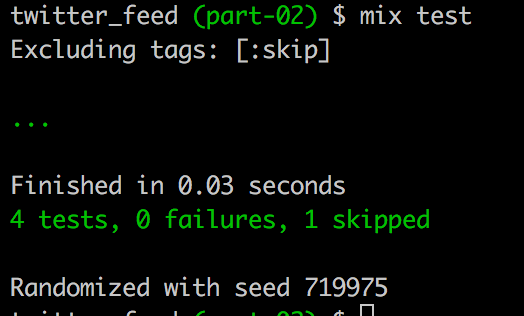
Parsing the individual fields of a tweet
The last thing we’ll tackle today is figuring out how to parse the individual fields of each tweet we retrieve. For now we’ll just grab the display name of the tweet. The display name is different from the handle, i.e. for the handle lolagil, the display name is lola.

Being able to test the parsing of each individual field will be helpful, so let’s set-up some testing for the Parser.
First we’ll create the test file.
Terminal
touch test/twitter_feed/parser_test.exsNow let’s create a test for the display name.
If we look in our sample data, we’ll see that the display name is an attribute within the .tweet div. So let’s set-up our test to reflect this.
/test/twitter_feed/parser_test.exs
defmodule TwitterFeed.ParserTest do
use ExUnit.Case, async: true
alias TwitterFeed.Parser
test "parsing of display_name" do
html_snippet = "<div class=\"tweet\" data-name=\"lola\"></div>"
assert Parser.parse_display_name(html_snippet) == "lola"
end
endSo we’re feeding a snippet of HTML into our parser and expecting an appropriate result.
Let’s update the parser.
/lib/twitter_feed/parser.ex
...
...
##################### PRIVATE FUNCTIONS #####################
defp parse_tweet(tweet_html) do
%Tweet {
display_name: parse_display_name(tweet_html)
}
end
defp parse_display_name(tweet_html) do
tweet_html
|> Floki.attribute("data-name")
|> hd()
end
endWe’ve added a parse_display_name function which surprise, surprise, parses the display name. We call into it from parse_tweet in order to populate the display_name value of our structure.
Let’s run our tests.
Terminal
mix test
Hmm, we’ve got a bit of a problem here as we’re trying to test a private function. Luckily there is a Hex package we can use that will help us out.
Now some people would argue that testing private functions is not appropriate, I think it is dependent on the situation, and in this case makes sense for the following reasons:
- It allows us to quickly determine if we have an issue with the parsing of a particular field.
- It avoids having to write a large and likely complicated test against
parse_tweets. To testparse_tweetswe would need to create a comprehensive HTML snippet in the test that captured all the fields we need to parse and we’d then need to check all these fields, all within one test. - It helps to document in our code what we are parsing within the HTML. For instance with our display name test in place it is very easy to see what we expect to be returned in the Twitter HTML when it comes to the display name.
- Another option would be to make the functions we want to test public instead of private… but this would add confusion as to how we’re expecting the
Parsermodule will be used within our code base. We don’t want modules external to theParserto call the individualparse_...` functions.
In any case, let’s update mix.exs and get the test passing. We’ll be using Publicist. As per the Publicist documentation, it maps private items to public when running under the Elixir test environment.
/mix.exs
defp deps do
[
{:excoveralls, "~> 0.8", only: :test},
{:httpoison, "~> 1.0"},
{:floki, "~> 0.20.0"},
{:publicist, "~> 1.1"}
]
end
endWe need to make a small change to the Parser.
/lib/twitter_feed/parser.ex
...
##################### PRIVATE FUNCTIONS #####################
defp parse_tweet(tweet_html) do
%Tweet {
display_name: parse_display_name(tweet_html)
}
end
use Publicist
defp parse_display_name(tweet_html) do
...Anything under the use Publicist line will be made public when running in the test environment.
Now we should have a passing test.
Terminal
mix deps.getTerminal
mix test
Perfect!
Finally, if you run the application with iex, the display name will be showing up in our returned data.
Terminal
iex -S mixTerminal
TwitterFeed.get_tweets("lolagil")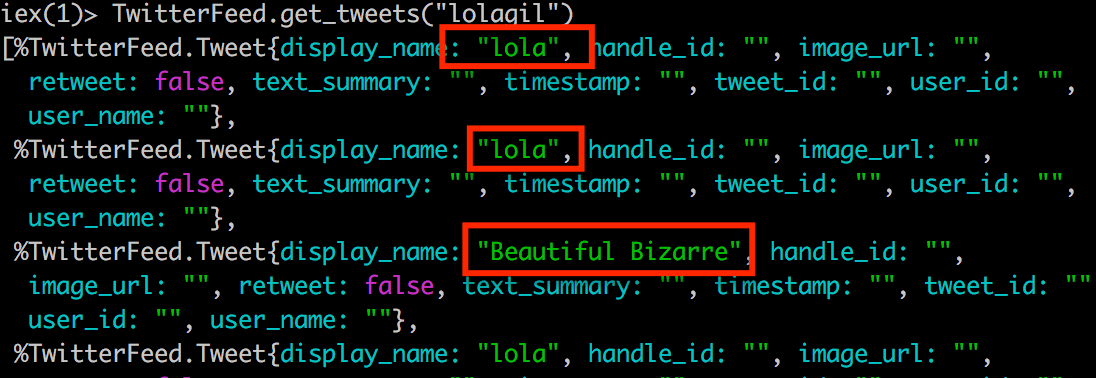
Notice that at the point in time that I ran this, the third tweet is a re-tweet, so has the display name of the original tweeter.
Generating documentation
To end things off let’s see how easy it is to create documentation with Elixir. All we need to do is update our dependencies in the mix.exs file, adding an entry for ex_doc.
/mix.exs
defp deps do
[
{:excoveralls, "~> 0.8", only: :test},
{:httpoison, "~> 1.0"},
{:floki, "~> 0.20.0"},
{:publicist, "~> 1.1"},
{:ex_doc, "~> 0.16", only: :dev, runtime: false}
]
endNow we’re good to go!
Terminal
mix deps.getTerminal
mix docs
Check them out in your browser, we can see that our comments for the Tweet struct are showing up as expected.

Pretty cool!
Summary
It’s seems like it’s been a long time coming, but we are finally starting to see our Twitter Scraper come together. Slowly but surely we’re building things up, and now that we’ve managed to parse out our first field, things should start to move along at a good pace.
In the next installment we’ll tackle the rest of our fields and eventually get back to our Scraper tests and functionality.
Thanks for reading and I hope you enjoyed the post!