At the end of Part 3 we finally got around to parsing out some data from the HTML we retrieved from Twitter. We’ll continue building out our Tweet struct and aim to have all our fields populated by the end of this post.
I’d encourage you to follow along, but if you want to skip directly to the code, it’s available on GitHub at: https://github.com/riebeekn/elixir-twitter-scraper.
Getting started
If you followed along with part 3 just continue on with the code you created in part 3. If not and you’d rather jump right into part 4, you can use a clone of part 3 as a starting point.
Clone the Repo
If grabbing the code from GitHub instead of continuing along from part 3, the first step is to clone the repo.
Terminal
git clone -b part-03 https://github.com/riebeekn/elixir-twitter-scraper twitter_feed
cd twitter_feed
mix deps.getOK, you’ve either gotten the code from GitHub or are using the existing code you created in Part 3, let’s get to parsing!
Parsing the rest of our fields
You’ll recall from part 3 we got to the point where we had parsed the display_name field of our struct.
We have 8 more fields to populate, we’ll be mucking about pretty much exclusively in the Parser module today, let’s get at it!
Parsing the user_id
The user_id, like many of the fields we want to capture, is an attribute of the .tweet div.
Let’s put together a test.
/test/twitter_feed/parser_test.ex
defmodule TwitterFeed.ParserTest do
use ExUnit.Case, async: true
alias TwitterFeed.Parser
test "parsing of display_name" do
html_snippet = "<div class=\"tweet\" data-name=\"lola\"></div>"
assert Parser.parse_display_name(html_snippet) == "lola"
end
test "parsing of user_id" do
html_snippet = "<div class=\"tweet\" data-user-id=\"2\"></div>"
assert Parser.parse_user_id(html_snippet) == 2
end
endVery simple, we’ve added a new test, parsing of user_id, that contains an HTML snippet with the data-user-id attribute and checks for the value of the attribute upon parsing.
Now for the implementation.
/lib/twitter_feed/parser.ex
...
##################### PRIVATE FUNCTIONS #####################
defp parse_tweet(tweet_html) do
%Tweet {
display_name: parse_display_name(tweet_html)
}
end
use Publicist
defp parse_display_name(tweet_html) do
tweet_html
|> Floki.attribute("data-name")
|> hd()
end
defp parse_user_id(tweet_html) do
tweet_html
|> Floki.attribute("data-user-id")
|> hd()
|> String.to_integer()
end
endVery similar to parse_display_name. We’re just using Floki to grab the value of the attribute, and then in this case, we convert it to an integer before returning it.
With that all in place we should now have a new test that passes.
Terminal
mix test
Looking good! We’ll be following a similar pattern for the rest of the fields. The code should be pretty similar to the 2 fields we’ve completed, so explanations will be kept to a minimum from here on out. Also, I suggest you re-run the tests after each field is added; but I’ll be skipping out on that for the sake of brevity.
Parsing the user_name
The user_name is contained within the .tweet div in a data-screen-name attribute.
Let’s add a test.
/test/twitter_feed/parser_test.ex
test "parsing of user_name" do
html_snippet = "<div class=\"tweet\" data-screen-name=\"SomeUserName\"></div>"
assert Parser.parse_user_name(html_snippet) == "SomeUserName"
endAnd now the implementation.
/lib/twitter_feed/parser.ex
defp parse_user_name(tweet_html) do
tweet_html
|> Floki.attribute("data-screen-name")
|> hd()
endParsing the tweet_id
The tweet_id is contained within the .tweet div in a data-tweet-id attribute.
The test.
/test/twitter_feed/parser_test.ex
test "parsing of tweet_id" do
html_snippet = "<div class=\"tweet\" data-tweet-id=\"1\"></div>"
assert Parser.parse_tweet_id(html_snippet) == 1
endThe implementation.
/lib/twitter_feed/parser.ex
defp parse_tweet_id(tweet_html) do
tweet_html
|> Floki.attribute("data-tweet-id")
|> hd()
|> String.to_integer()
endParsing the timestamp
The timestamp unlike most of our fields is not a direct attribute of the .tweet div. We need to search out a span with a class of _timestamp within the .tweet div and then grab the data-time-ms attribute.
The test.
/test/twitter_feed/parser_test.ex
test "parsing of timestamp" do
html_snippet = "<span class=\"_timestamp\" data-time-ms=\"1519339506000\"</span>"
assert Parser.parse_timestamp(html_snippet) == "2018-02-22 22:45:06.000Z"
endThe implementation.
/lib/twitter_feed/parser.ex
defp parse_timestamp(tweet_html) do
tweet_html
|> Floki.find("._timestamp")
|> Floki.attribute("data-time-ms")
|> hd()
|> String.to_integer()
|> DateTime.from_unix!(:millisecond)
|> DateTime.to_string()
endNot too tricky, we’ve got a few whacky manipulations to get the timestamp in the format we want, but nothing crazy. If you are curious about what some of these functions do, check out the documentation in iex, for example.
Terminal
iexTerminal
h DateTime.from_unix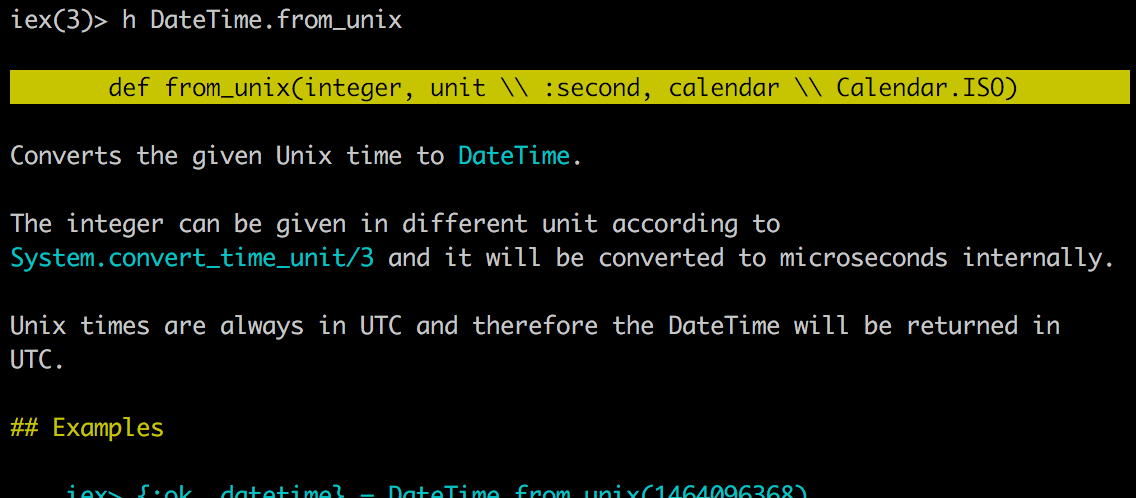
Parsing the tweet text
We’ll derive the text_summary from the Tweet text which we find within a p tag with a class of tweet-text.
The test.
/test/twitter_feed/parser_test.ex
test "parsing of tweet_text" do
html_snippet = "<p class=\"tweet-text\">some text</p>"
assert Parser.parse_text(html_snippet) == "some text"
endThe implementation.
/lib/twitter_feed/parser.ex
defp parse_text(tweet_html) do
tweet_html
|> Floki.find(".tweet-text")
|> Floki.text()
|> String.trim()
endNothing we haven’t seen before, we’re applying a String.trim() at the end in order to clean up any extraneous whitespace.
Parsing the image_url
The image_url is nested in a div within the .tweet div. The nested div has a class of .AdaptiveMedia-photoContainer and the URL is specified in the data-image-url attribute.
The test.
/test/twitter_feed/parser_test.ex
test "parsing of tweet_image" do
html_snippet = """
<div class=\"AdaptiveMedia-photoContainer\"
data-image-url=\"https://pbs.twimg.com/media/123.jpg\">
</div>
"""
assert Parser.parse_image(html_snippet) == "https://pbs.twimg.com/media/123.jpg"
endThe implementation.
/lib/twitter_feed/parser.ex
defp parse_image(tweet_html) do
tweet_html
|> Floki.find(".AdaptiveMedia-photoContainer")
|> Floki.attribute("data-image-url")
|> Floki.text()
endAgain pretty simple.
Parsing the retweet field
In the case of a retweet, the .tweet will contain a data-retweeter attribute. So we just need to check if that attribute exists or not.
We need two tests for this field, one to check the correct functionality when the Tweet is not a retweet and another for when it is.
/test/twitter_feed/parser_test.ex
test "parsing of retweeter when it is a retweet" do
html_snippet = "<div class=\"tweet\" data-retweeter=\"TorontoComms\"></div>"
assert Parser.parse_is_retweet(html_snippet) == true
end
test "parsing of retweeter when it is not a retweet" do
html_snippet = "<div class=\"tweet\"></div>"
assert Parser.parse_is_retweet(html_snippet) == false
endThe implementation.
/lib/twitter_feed/parser.ex
defp parse_is_retweet(tweet_html) do
tweet_html
|> Floki.attribute("data-retweeter")
|> Enum.count() == 1
endIf you haven’t been running the tests as we’ve been adding the fields, now would be a good time to check that everything is working!
Terminal
mix test
Populating the Struct
The next step is to populate the Tweet structure with the fields we’ve parsed. This is simple, all we need to do is call into our parse functions.
/lib/twitter_feed/parser.ex
##################### PRIVATE FUNCTIONS #####################
defp parse_tweet(tweet_html) do
%Tweet {
user_id: parse_user_id(tweet_html),
user_name: parse_user_name(tweet_html),
display_name: parse_display_name(tweet_html),
tweet_id: parse_tweet_id(tweet_html),
timestamp: parse_timestamp(tweet_html),
text_summary: parse_text(tweet_html) |> truncate(),
image_url: parse_image(tweet_html),
retweet: parse_is_retweet(tweet_html)
}
endNotice we also have a truncate/1 function we are calling to create the text summary. We’ll need to create this function, so let’s add a few more tests and an implementation for this.
/test/twitter_feed/parser_test.ex
test "truncation of text that does not exceed 30 chars" do
assert Parser.truncate("some text") == "some text"
end
test "truncation of text over 30 chars is truncated" do
text = "This is some text that is 31 ch"
assert Parser.truncate(text) == "This is some text that is 31 c..."
endWe can see by the tests that we are expecting the truncate/1 function to truncate any text that exceeds 30 characters. It will add 3 trailing periods to the text to indicate it has been truncated, meaning the truncated text will be 33 characters total.
The implementation.
/lib/twitter_feed/parser.ex
defp truncate(text) do
if (String.length(text)) > 30 do
String.slice(text, 0, 30) <> "..."
else
text
end
endNot too tricky, we’re just using some existing String functions to accomplish the truncation.
Let’s make sure everything is still passing:
Terminal
mix test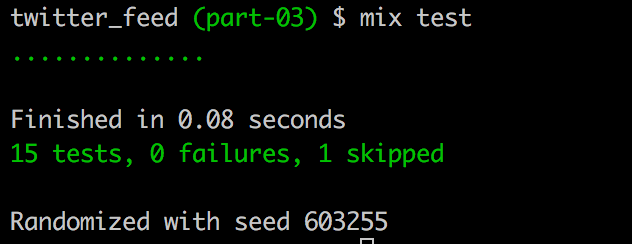
Great! Now let’s see how this looks in iex.
Terminal
iex -S mixTerminal
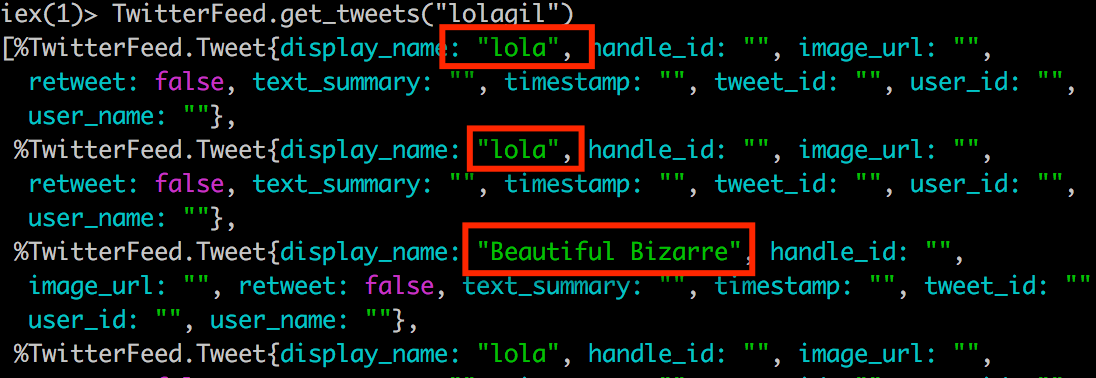
TwitterFeed.get_tweets("lolagil")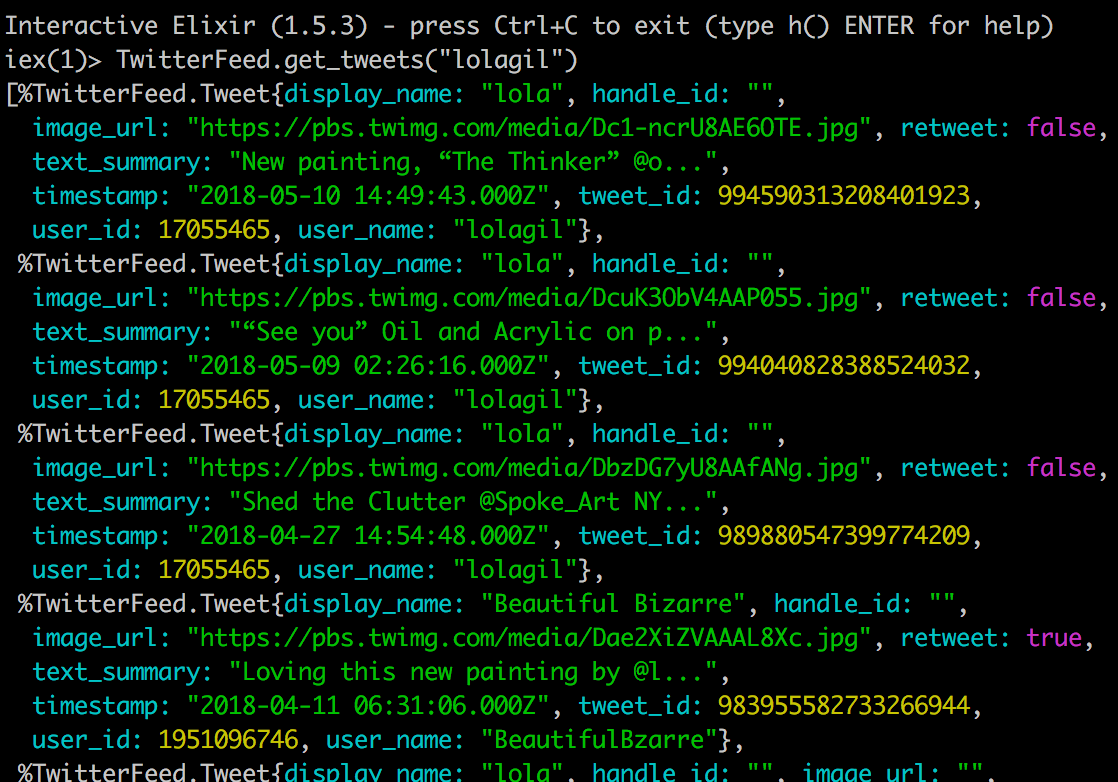
Perfect, things are looking good. Notice the 4th tweet in the screen-shot above is correctly identified as a retweet. The display_name, user_name and user_id fields are all correctly populated with the values for the original author.
Parsing the handle_id
You’ve probably noticed we have yet to parse the handle_id. This is because this is a little tricky and is actually dependent on some of the existing fields that we’ve now parsed.
Regardless of whether a Tweet is a retweet or not, the handle_id should always refer to the current feed we are retrieving data from. In the case when the Tweet is not a retweet, the handle_id is the same as the user_id. When it is a retweet, we can parse out the handle_id from an anchor tag that refers to the user who retweeted the Tweet.
Let’s see some tests, hopefully a concrete example will help to clarify what is going on.
/test/twitter_feed/parser_test.ex
test "parsing of handle_id when it is not a retweet" do
assert Parser.parse_handle_id(false, 123, "some html") == 123
end
test "parsing of handle_id when it is a retweet" do
html_snippet = """
<span class=\"js-retweet-text\">
<a data-user-id=\"19377913\"><b>City of Toronto</b></a> Retweeted
</span>
"""
assert Parser.parse_handle_id(true, 123, html_snippet) == 19377913
endLooking at the call to the parse_handle_id/3 function in the tests we see it takes in the following parameters:
- A boolean to indicate whether the Tweet is a retweet or not.
- An integer representing the
user_idof the Tweet. - The
.tweetdiv for the current Tweet we are processing, just like all our other parse functions.
We can see in the first test where the Tweet is not a retweet, we expect the handle_id to equal the value passed in to the user_id parameter.
In the second test we’re handling a retweet and need to parse the handle_id out of the anchor tag.
The implementation.
/lib/twitter_feed/parser.ex
defp parse_handle_id(false, user_id, _tweet_html) do
user_id
end
defp parse_handle_id(true, _user_id, tweet_html) do
tweet_html
|> Floki.find(".js-retweet-text > a")
|> Floki.attribute("data-user-id")
|> hd()
|> String.to_integer()
endWe’re using pattern matching to determine which version of parse_handle_id/3 to run. The implementations themselves are straight forward.
We should now have a couple more passing tests.
Terminal
mix test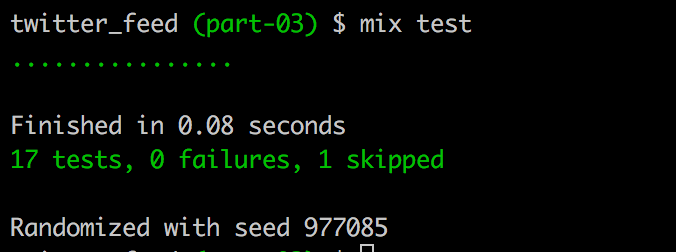
Now let’s see how we can hook this into the Tweet struct.
/lib/twitter_feed/parser.ex
##################### PRIVATE FUNCTIONS #####################
defp parse_tweet(tweet_html) do
user_id = parse_user_id(tweet_html)
is_retweet = parse_is_retweet(tweet_html)
%Tweet {
handle_id: parse_handle_id(is_retweet, user_id, tweet_html),
user_id: user_id,
user_name: parse_user_name(tweet_html),
display_name: parse_display_name(tweet_html),
tweet_id: parse_tweet_id(tweet_html),
timestamp: parse_timestamp(tweet_html),
text_summary: parse_text(tweet_html) |> truncate(),
image_url: parse_image(tweet_html),
retweet: is_retweet
}
endSo we’ve pulled out the calls to parse_user_id and is_retweet in order to their return values available when we call into parse_handle_id. We also replace the function calls that we were making within the struct for user_id and retweet with the user_id and is_retweet variables.
Let’s have another look in iex.
Terminal
iex -S mixTerminal
TwitterFeed.get_tweets("lolagil")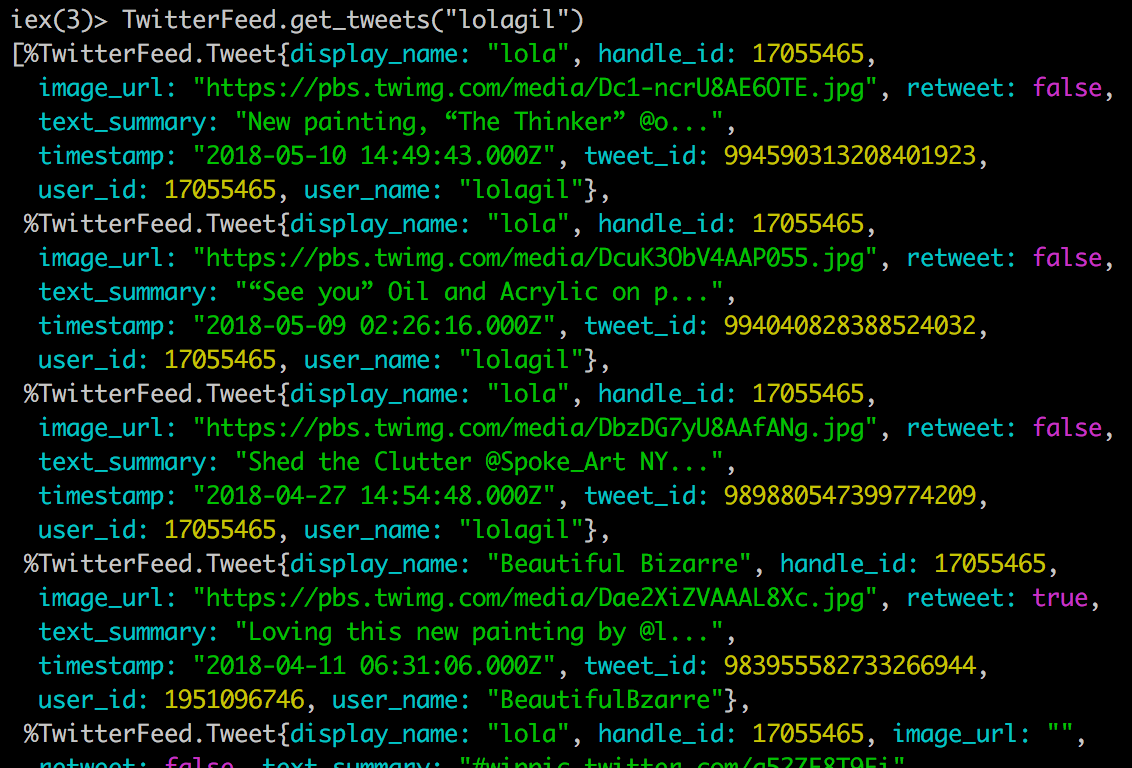
And there we go, the handle_id is now properly populated, both for original and retweeted Tweets.
Summary
Slowly things are starting to come together, all our fields are parsed and being returned via the Tweet structure. In the next installment we’ll switch back to working on the Scraper module.
Thanks for reading and I hope you enjoyed the post!