In part 5 we used JSON calls to retrieve tweets from pages other than the Twitter home page. In this post we’ll add a new structure to our application to make it easy for applications that are consuming our code to know whether more tweets exist and how to retrieve them.
I’d encourage you to follow along, but if you want to skip directly to the code, it’s available on GitHub at: https://github.com/riebeekn/elixir-twitter-scraper.
Getting started
If you followed along with part 5 just continue on with the code you created in part 5. If not and you’d rather jump right into part 6, you can use a clone of part 5 as a starting point.
Clone the Repo
If grabbing the code from GitHub instead of continuing along from part 5, the first step is to clone the repo.
Terminal
git clone -b part-05 https://github.com/riebeekn/elixir-twitter-scraper twitter_feed
cd twitter_feed
mix deps.getOK, you’ve either gotten the code from GitHub or are using the existing code you created in Part 5, let’s get to it!
A review of where we’re at
Let’s start by having a look at where we’re currently at. The current output of a call into our application yields a list of Tweets.
Terminal
iex -S mixTerminal
TwitterFeed.get_tweets("lolagil")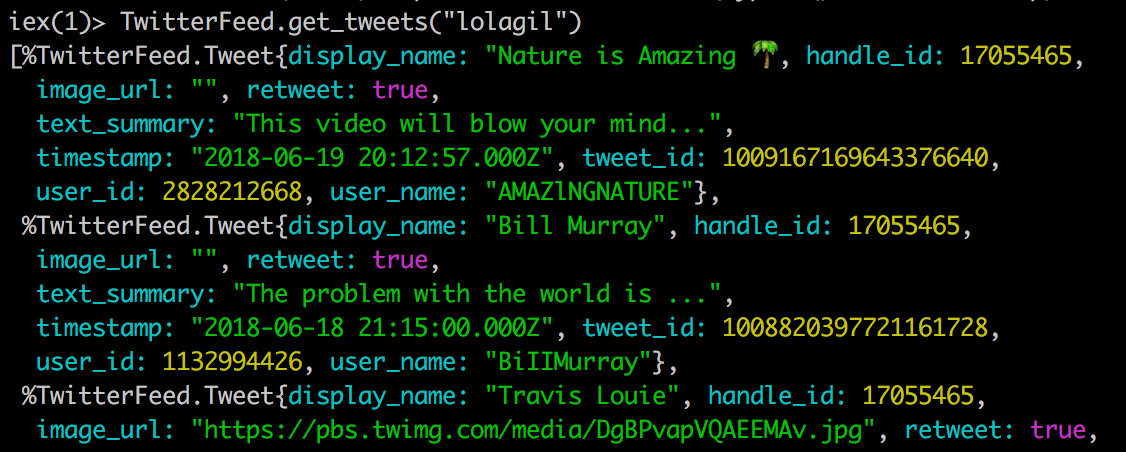
The main problem with this approach is a consumer of our application has no indication of whether more Tweets exist; nor is it super easy for them to determine the value they should be passing into the start_after_tweet parameter, i.e.
Remember the start_after_tweet value needs to be the id of the last tweet retrieved. So a consuming application would need to keep track of this in order to grab subsequent pages of tweets. Not a big deal, but not very user friendly either.
So let’s think about how we can improve things.
Restructuing our return values
To remedy this, we’ll add a new struct that will contain our list of Tweets, but also some general information about the feed, namely whether more tweets exist and what the id of the last tweet retrieved was.
Adding the new struct
Let’s add our new struct above the definition for our existing Tweet struct.
/lib/twitter_feed/structs.ex
defmodule TwitterFeed.Feed do
@moduledoc """
Struct representing a twitter feed.
## Fields
- last_tweet_retrieved: the id of the last tweet retrieved.
- more_tweets_exist: true | false indicator of whether there are more tweets.
- tweets: [%TwitterFeed.Tweet] - a list of the tweets retrieved.
"""
defstruct [
last_tweet_retrieved: 0,
more_tweets_exist: false,
tweets: []
]
end
defmodule TwitterFeed.Tweet do
...
...Pretty straight-forward, we’ve added a new struct to structs.ex called Feed. This will supply us with the last tweet retrieved and whether more tweets exists, along with our list of tweets.
Making use of the new struct
The next step is to update parser.ex to make use of the new structure. We now need to determine and populate the last_tweet_retrieved and a more_tweets_exist fields of our new struct. Let’s have a look at how we can go about accomplishing this.
We’re going to need to deal with parsing both the HTML and JSON responses; let’s start with the HTML response.
Parsing our new fields from the HTML response
We’ll add 2 new private methods in parser.ex to handle the new fields. We’ll add a parse_html_min_position and parse_html_has_more_items method, and of course we want to add tests for these, so let’s start off with the tests for figuring out the min_position value.
/test/twitter_feed/parser_test.exs
test "parsing of min position from html response" do
html_snippet = "<div class=\"stream-container\" data-min-position=\"33\">"
assert Parser.parse_html_min_position(html_snippet) == 33
end
test "parsing of min position from html response should return 0 when the page has no tweets" do
html_snippet = "<div class=\"stream-container\" data-min-position=\"\">"
assert Parser.parse_html_min_position(html_snippet) == 0
endFor the HTML response, the data-min-position attribute contains the id of the last tweet retrieved. We have also added a test for the situation where the scraper is hitting a Twitter page that has no tweets. In this case we expect a 0 to be returned for the id.
Next we need some tests for determining if more tweets exist:
/test/twitter_feed/parser_test.exs
test "parsing of has more items when there are no more items" do
html_snippet = "<div class=\"timeline-end has-items \">"
assert Parser.parse_html_has_more_items(html_snippet) == false
end
test "parsing of has more items when there are more items" do
html_snippet = "<div class=\"timeline-end has-items has-more-items\">"
assert Parser.parse_html_has_more_items(html_snippet) == true
endLooking at our tests we can see that when the div with the class of timeline-end contains the has-more-items class… we have more tweets. When it is missing we don’t.
Let’s add the implementation of our new methods. Note: make sure you place these new methods under the use Publicist directive so that they can be accessed in the tests.
/lib/twitter_feed/parser.ex
defp parse_html_has_more_items(html_response) do
html_response
|> Floki.find(".has-more-items")
|> Enum.count() == 1
end
defp parse_html_min_position(html_response) do
min_position = html_response
|> Floki.find(".stream-container")
|> Floki.attribute("data-min-position")
|> hd()
if (min_position |> String.length() == 0) do
0
else
String.to_integer(min_position)
end
endPretty simple, with the parse_html_has_more_items function we simply check for the existance of the has-more-items class. In the case of parse_html_min_position we parse and convert the data-min-position value to an integer while taking into account the scenario where it is empty (i.e. no tweets were retrieved).
Our tests should now be passing.
Terminal
mix test
Parsing our new fields from the JSON response
In the case of the JSON response there is very little to do; the response itself contains the information we’re after in the min_postition and has_more_items fields:

The only thing we need to do is convert the min_position value to an integer, and return 0 in cases where it is missing.
So let’s add a few new tests for that.
/test/twitter_feed/parser_test.exs
test "parsing of min position from json response" do
assert Parser.parse_json_min_position("33") == 33
end
test "parsing of min position from json response should return 0 when the page has no tweets" do
assert Parser.parse_json_min_position(nil) == 0
endAnd now the implementation.
/lib/twitter_feed/parser.ex
defp parse_json_min_position(min_position) do
if (min_position == nil) do
0
else
min_position |> String.to_integer()
end
endAnd with that we should have another 2 passing tests.
Terminal
mix test
Updating the main parser methods
Now it is time to update the main parse_tweets methods to make use of the new struct and parse methods.
Let’s start by updating the HTML version of parse_tweets.
/lib/twitter_feed/parser.ex
defmodule TwitterFeed.Parser do
@moduledoc false
alias TwitterFeed.{ Feed, Tweet }
def parse_tweets(html, :html) do
tweet_html =
html
|> Floki.find(".tweet")
%Feed {
last_tweet_retrieved: html |> parse_html_min_position(),
more_tweets_exist: html |> parse_html_has_more_items,
tweets: Enum.map(tweet_html, fn(x) -> parse_tweet(x) end)
}
endFirst we’ve added a new alias to include the Feed structure, i.e. alias TwitterFeed.{ Feed, Tweet }.
In the function itself we’re now returning our new structure by making use of the newly created functions that parse out the min position and more items values; the tweets list is populated in the same way as before.
Now calling into the method with iex yields the following:
Terminal
iex -S mixTerminal
TwitterFeed.get_tweets("lolagil")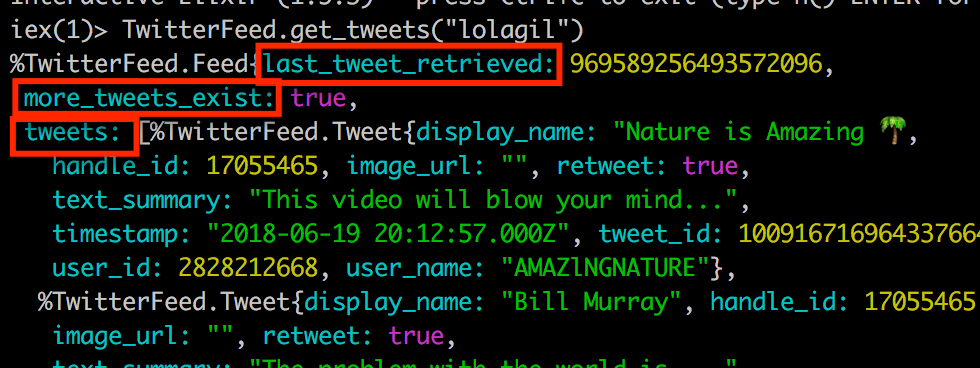
Let’s also update the JSON version of the method.
/lib/twitter_feed/parser.ex
def parse_tweets(json, :json) do
parsed_json =
json
|> Poison.Parser.parse!()
tweet_html =
parsed_json["items_html"]
|> String.trim()
|> Floki.find(".tweet")
%Feed {
last_tweet_retrieved: parsed_json["min_position"] |> parse_json_min_position(),
more_tweets_exist: parsed_json["has_more_items"],
tweets: Enum.map(tweet_html, fn(x) -> parse_tweet(x) end)
}
endPretty similar to what we’ve done with the HTML version. The only real difference is that we parse the JSON using Poison and then retrieve the tweet HTML, min position and has more items data from the results returned from Poison.
If we have a look at a JSON based response from iex we’ll see our new struct.
Terminal
iex -S mixTerminal
TwitterFeed.get_tweets("lolagil", 948759471467118592)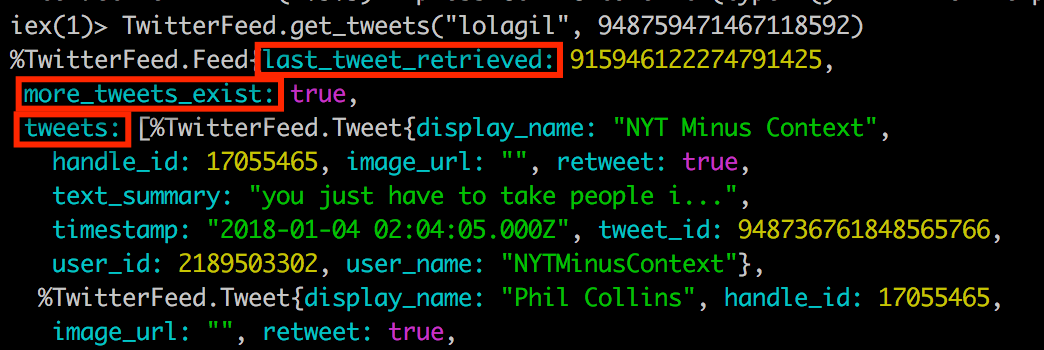
What about our scraper tests?
The last thing we need to deal with is our scraper tests; the return value change will be causing them to fail.
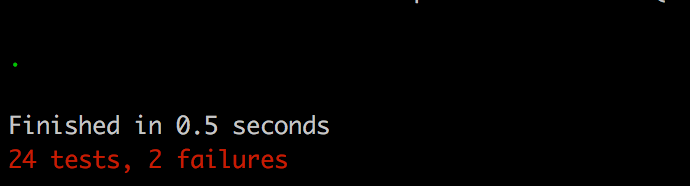
The fix is very easy however, we just need to take into account the new structure and while we’re at it add some additional checks for the last_tweet_retrieved and more_tweets_exist values.
In the updated test we’re changing the name of the local variable assigned to the Scraper.scrape result from tweets to feed as the return value is now our new Feed structure. We then perform assertions against the new fields in our structure, i.e. last_tweet_retrieved and more_tweets_exist. For the existing statements where we were assigning the first and last tweets we now do so via feed.tweets instead of directly. The full updated listing for scraper_test.ex is below
/test/twitter_feed/scraper_test.exs
defmodule TwitterFeed.ScraperTest do
use ExUnit.Case, async: true
alias TwitterFeed.{ Scraper }
test "scraping on non-existant handle will return 404" do
{:error, reason} = Scraper.scrape(:non_existant_handle, 0)
assert reason =~ "404 error, that handle does not exist"
end
test "scraping the first page of tweets" do
feed = Scraper.scrape("someTwitterHandle", 0)
assert feed.last_tweet_retrieved == 948759471467118592
assert feed.more_tweets_exist == true
assert Enum.count(feed.tweets) == 20
first_tweet = feed.tweets |> hd()
assert first_tweet.handle_id == 17055465
assert first_tweet.tweet_id == 989880547399774209
assert first_tweet.user_id == 17055465
assert first_tweet.user_name == "lolagil"
assert first_tweet.display_name == "lola"
assert first_tweet.timestamp == "2018-04-27 14:54:48.000Z"
assert first_tweet.text_summary == "Shed the Clutter @Spoke_Art NY..."
assert first_tweet.image_url == "https://pbs.twimg.com/media/DbzDG7yU8AAfANg.jpg"
assert first_tweet.retweet == false
last_tweet = feed.tweets |> List.last()
assert last_tweet.handle_id == 17055465
assert last_tweet.tweet_id == 948266826315829248
assert last_tweet.user_id == 3367318323
assert last_tweet.user_name == "viviunuu"
assert last_tweet.display_name == "culera"
assert last_tweet.timestamp == "2018-01-02 18:56:43.000Z"
assert last_tweet.text_summary == "this is how much i’m striving ..."
assert last_tweet.image_url == "https://pbs.twimg.com/media/DSjrplLXcAA0j-S.jpg"
assert last_tweet.retweet == true
end
test "scraping the second page of tweets" do
feed = Scraper.scrape("someTwitterHandle", 1234)
assert feed.last_tweet_retrieved == 915946122274791425
assert feed.more_tweets_exist == true
assert Enum.count(feed.tweets) == 19
first_tweet = feed.tweets |> hd()
assert first_tweet.handle_id == 17055465
assert first_tweet.tweet_id == 948736761848565766
assert first_tweet.user_id == 2189503302
assert first_tweet.user_name == "NYTMinusContext"
assert first_tweet.display_name == "NYT Minus Context"
assert first_tweet.timestamp == "2018-01-04 02:04:05.000Z"
assert first_tweet.text_summary == "you just have to take people i..."
assert first_tweet.image_url == ""
assert first_tweet.retweet == true
last_tweet = feed.tweets |> List.last()
assert last_tweet.handle_id == 17055465
assert last_tweet.tweet_id == 915946122274791425
assert last_tweet.user_id == 17055465
assert last_tweet.user_name == "lolagil"
assert last_tweet.display_name == "lola"
assert last_tweet.timestamp == "2017-10-05 14:25:47.000Z"
assert last_tweet.text_summary == "Can NOT wait!!!https://twitter..."
assert last_tweet.image_url == ""
assert last_tweet.retweet == false
end
endAnd with that we are back to pass.
Terminal
mix test
Summary
We now have a much more user friendly implementation. At this point we are very close to being done with this series of posts. Next time we’ll add some error handling, at which point our scraper will be done and dusted!
Thanks for reading and I hope you enjoyed the post!