At the end of Part 4 we finished parsing all the fields we want to extract from a Tweet. We’re now going to integrate our changes into the Scraper module and look at how to retrieve subsequent pages of Tweets.
I’d encourage you to follow along, but if you want to skip directly to the code, it’s available on GitHub at: https://github.com/riebeekn/elixir-twitter-scraper.
Getting started
If you followed along with part 4 just continue on with the code you created in part 4. If not and you’d rather jump right into part 5, you can use a clone of part 4 as a starting point.
Clone the Repo
If grabbing the code from GitHub instead of continuing along from part 4, the first step is to clone the repo.
Terminal
git clone -b part-04 https://github.com/riebeekn/elixir-twitter-scraper twitter_feed
cd twitter_feed
mix deps.getOK, you’ve either gotten the code from GitHub or are using the existing code you created in Part 4, let’s get to it!
Back to the Scraper
We’ve mostly been working with the Parser module lately; we’re going to switch gears and look at how we can integrate the changes we’ve made into the Scraper module.
Starting with some testing
The first thing we’ll do is update our Scraper tests. If you recall, we currently have pretty sparse testing of the Scraper module and we’re currently not even running one of them.
Terminal
mix test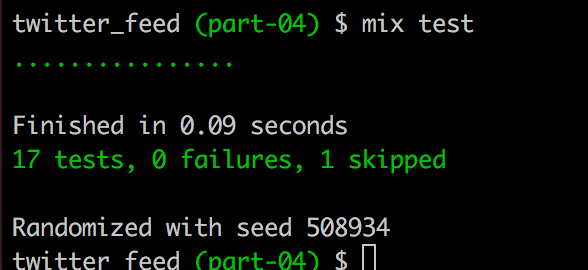
So let’s concentrate on that skipped test for now. We’re going to replace the test altogether as currently it really doesn’t do much:
Instead we will create a test based on the test data we placed in test/data back in part 3, let’s get to it!
/test/twitter_feed/scraper_test.exs
defmodule TwitterFeed.ScraperTest do
use ExUnit.Case, async: true
alias TwitterFeed.{ Scraper }
test "scraping on non-existant handle will return 404" do
{:error, reason} = Scraper.scrape(:non_existant_handle, 0)
assert reason =~ "404 error, that handle does not exist"
end
test "scraping the first page of tweets" do
tweets = Scraper.scrape("someTwitterHandle", 0)
assert Enum.count(tweets) == 20
first_tweet = tweets |> hd()
assert first_tweet.handle_id == 17055465
assert first_tweet.tweet_id == 989880547399774209
assert first_tweet.user_id == 17055465
assert first_tweet.user_name == "lolagil"
assert first_tweet.display_name == "lola"
assert first_tweet.timestamp == "2018-04-27 14:54:48.000Z"
assert first_tweet.text_summary == "Shed the Clutter @Spoke_Art NY..."
assert first_tweet.image_url == "https://pbs.twimg.com/media/DbzDG7yU8AAfANg.jpg"
assert first_tweet.retweet == false
last_tweet = tweets |> List.last()
assert last_tweet.handle_id == 17055465
assert last_tweet.tweet_id == 948266826315829248
assert last_tweet.user_id == 3367318323
assert last_tweet.user_name == "viviunuu"
assert last_tweet.display_name == "culera"
assert last_tweet.timestamp == "2018-01-02 18:56:43.000Z"
assert last_tweet.text_summary == "this is how much i’m striving ..."
assert last_tweet.image_url == "https://pbs.twimg.com/media/DSjrplLXcAA0j-S.jpg"
assert last_tweet.retweet == true
end
endSo based on the data in test/data/twitter.html we can reliably set-up our test to expect certain values… and this is exactly what we are doing in the "scraping the first page of tweets" test.
Let’s have a look at the call to Scraper.scrape.
The second parameter with a value of 0 indicates we want to process the first page of tweets. The first parameter can be any value as we ignore the handle in our mock:
We now have 17 full tests with nothing being skipped.
Terminal
mix test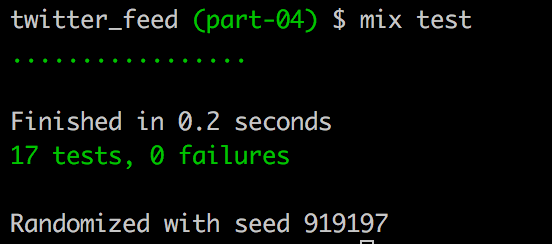
Scraping the 2nd page of Tweets
So this works great, how about if we want to retrieve the 2nd page of tweets however? Let’s set up a test for this and see what happens. We’ll create a test similar to what we did for the first page, once again we’ll need to set-up our mock, this time we’ll retrieve the JSON result.
Adding some test data
Based on the data in test/data/twitter.html the last tweet we retrieved had an id of 948759471467118592. So our JSON request for the second page of tweets is going to be: https://twitter.com/i/profiles/show/lolagil/timeline/tweets?include_available_features=1&include_entities=1&max_position=948759471467118592&reset_error_state=false
You can run this in your browser to get the JSON response and move it into the test/data folder, or just download the response I’ve previously retrieved and saved on GitHub:
Terminal
curl -L -O https://raw.githubusercontent.com/riebeekn/elixir-twitter-scraper/master/test/data/twitter.json
mv twitter.json test/dataAdding the JSON call
First off let’s update our API to include a new call to grab the JSON response.
/lib/twitter_feed/twitter_api/api.ex
defmodule TwitterFeed.TwitterApi.Api do
@moduledoc false
@callback get_home_page(handle :: String.t) :: String.t
@callback get_tweets(handle :: String.t, last_tweet_retrieved :: Integer.t) :: String.t
endWe’ve added a get_tweets method that will be used to get the next 20 tweets (recall Twitter sends us back 20 tweets at a time) based on the last tweet we’ve previously retrieved.
We’ll update the concrete implementation.
/lib/twitter_feed/twitter_api/http_client.ex
defmodule TwitterFeed.TwitterApi.HttpClient do
@moduledoc false
@behaviour TwitterFeed.TwitterApi.Api
alias TwitterFeed.TwitterApi.UrlBuilder
def get_home_page(handle) do
UrlBuilder.build_html_url(handle)
|> HTTPoison.get()
end
def get_tweets(handle, last_tweet_retrieved) do
UrlBuilder.build_json_url(handle, last_tweet_retrieved)
|> HTTPoison.get()
end
endPretty simple, we just call into the UrlBuilder to build the JSON specific URL and then use HTTPoison to make the request.
Our mock is also straight-forward. We just change the extension of the file we’re loading depending on whether we want the JSON or HTML file.
/test/mocks/twitter_api_mock.ex
defmodule TwitterFeed.Mocks.TwitterApiMock do
@behaviour TwitterFeed.TwitterApi.Api
def get_home_page(:non_existant_handle) do
{:ok, %{status_code: 404}}
end
def get_home_page(_handle) do
load_from_file("html")
end
def get_tweets(_handle, _last_tweet_retrieved) do
load_from_file("json")
end
defp load_from_file(extension) do
body =
Path.expand("#{File.cwd!}/test/data/twitter.#{extension}")
|> File.read!
{:ok, %{status_code: 200, body: body}}
end
endWe’ve also done a bit of refactoring; moving the File consumption code to a private function to reduce code duplication.
Updating the Scraper
Now we just need to update our Scraper code to handle grabbing the second page of tweets. We’re going to start by changing our scrape method to explicitly match our scenarios. So let’s update the current scrape function.
/lib/twitter_feed/scraper.ex
defmodule TwitterFeed.Scraper do
@moduledoc false
@twitter_api Application.get_env(:twitter_feed, :twitter_api)
alias TwitterFeed.Parser
def scrape(handle, 0) do
case @twitter_api.get_home_page(handle) do
{:ok, %{status_code: 200, body: body}} ->
body
|> Parser.parse_tweets()
{:ok, %{status_code: 404}} ->
return_404()
end
end
defp return_404 do
{:error, "404 error, that handle does not exist"}
end
endWe are now explicitly pattern matching on the scenario where we are requesting the first page of tweets (as 0 is being passed in as the start_after_tweet value). In this case we know we are looking to retrieve the first page of tweets and thus call into get_home_page.
Let’s add a 2nd scrape method that we can use for grabbing subsequent pages. For now we won’t worry about parsing the response, we’ll just return the body of the response.
/lib/twitter_feed/scraper.ex
def scrape(handle, start_after_tweet) do
case @twitter_api.get_tweets(handle, start_after_tweet) do
{:ok, %{status_code: 200, body: body}} ->
body
{:ok, %{status_code: 404}} ->
return_404()
end
endPretty simple, when the 2nd parameter is non-zero we know we want to execute a JSON request so we call into the new API method, get_tweets, to do so.
If we try this in iex we’ll see a JSON response.
Terminal
iex -S mixTerminal
TwitterFeed.get_tweets("lolagil", 948759471467118592)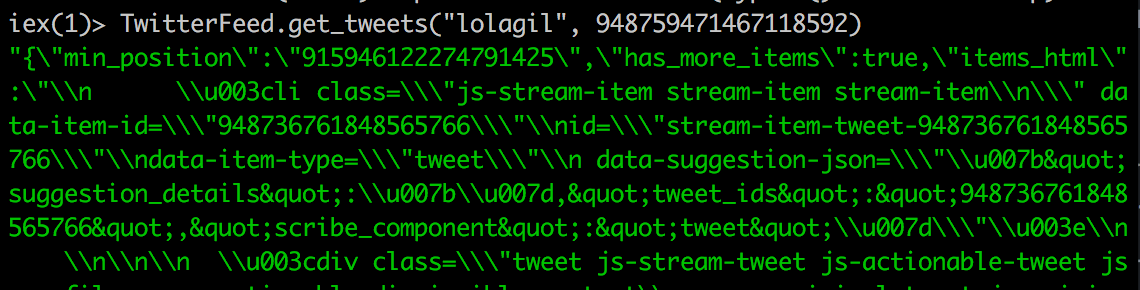
Looks good, we’re retrieving the JSON as expected.
Next we’re going to want to actually parse the JSON response, similar to what we do with the HTML response… so let’s start by adding a new test.
/test/twitter_feed/scrapper_test.exs
test "scraping the second page of tweets" do
tweets = Scraper.scrape("someTwitterHandle", 1234)
assert Enum.count(tweets) == 19
first_tweet = tweets |> hd()
assert first_tweet.handle_id == 17055465
assert first_tweet.tweet_id == 948736761848565766
assert first_tweet.user_id == 2189503302
assert first_tweet.user_name == "NYTMinusContext"
assert first_tweet.display_name == "NYT Minus Context"
assert first_tweet.timestamp == "2018-01-04 02:04:05.000Z"
assert first_tweet.text_summary == "you just have to take people i..."
assert first_tweet.image_url == ""
assert first_tweet.retweet == true
last_tweet = tweets |> List.last()
assert last_tweet.handle_id == 17055465
assert last_tweet.tweet_id == 915946122274791425
assert last_tweet.user_id == 17055465
assert last_tweet.user_name == "lolagil"
assert last_tweet.display_name == "lola"
assert last_tweet.timestamp == "2017-10-05 14:25:47.000Z"
assert last_tweet.text_summary == "Can NOT wait!!!https://twitter..."
assert last_tweet.image_url == ""
assert last_tweet.retweet == false
endThe values in the test are based on the test/data/twitter.json data.
Terminal
mix testIf we run the test, it will of course currently fail.
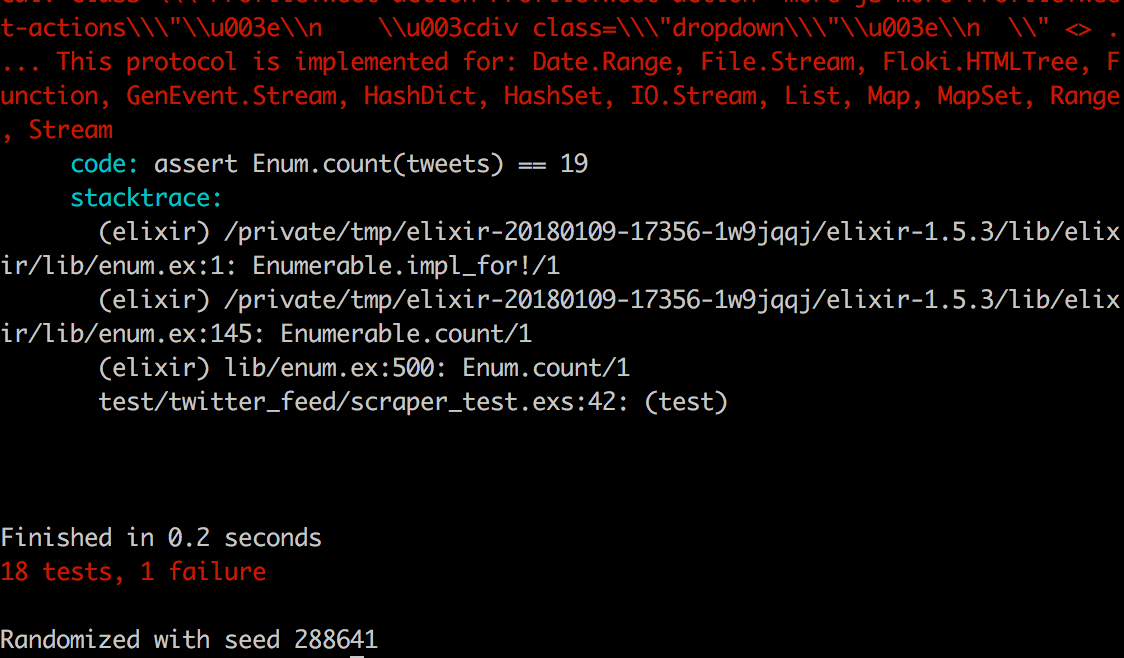
In order to get this test passing we’re going to need to parse the JSON content, and we’ll use a third party library to do so, Poison.
Let’s add it to mix.exs and run mix deps.get to update the dependencies.
/mix.exs
defp deps do
[
{:excoveralls, "~> 0.8", only: :test},
{:httpoison, "~> 1.0"},
{:floki, "~> 0.20.0"},
{:publicist, "~> 1.1"},
{:ex_doc, "~> 0.18.0", only: :dev, runtime: false},
{:poison, "~> 3.1"}
]
endTerminal
mix deps.get
With that out of the way, let’s update our Scraper method to call into the Parser.
/lib/twitter_feed/scraper.ex
defmodule TwitterFeed.Scraper do
@moduledoc false
@twitter_api Application.get_env(:twitter_feed, :twitter_api)
alias TwitterFeed.Parser
def scrape(handle, 0) do
case @twitter_api.get_home_page(handle) do
{:ok, %{status_code: 200, body: body}} ->
body
|> Parser.parse_tweets(:html)
{:ok, %{status_code: 404}} ->
return_404()
end
end
def scrape(handle, start_after_tweet) do
case @twitter_api.get_tweets(handle, start_after_tweet) do
{:ok, %{status_code: 200, body: body}} ->
body
|> Parser.parse_tweets(:json)
{:ok, %{status_code: 404}} ->
return_404()
end
end
defp return_404 do
{:error, "404 error, that handle does not exist"}
end
endSo both implementations of scrape now call into the Parser module, and similar to what we did with our mock, we pass in an indication of whether the data is in HTML or JSON format, i.e. Parser.parse_tweets(:html) for our first scrape function and Parser.parse_tweets(:json) for the second.
Now let’s update the Parser. We’ll add a second parse function that will handle the JSON response. Also our first function will change slightly to take in an :html atom indicating we are parsing an HTML response.
/lib/twitter_feed/parser.ex
def parse_tweets(html, :html) do
tweet_html =
html
|> Floki.find(".tweet")
Enum.map(tweet_html, fn(x) -> parse_tweet(x) end)
end
def parse_tweets(json, :json) do
parsed_json =
json
|> Poison.Parser.parse!()
tweet_html =
parsed_json["items_html"]
|> String.trim()
|> Floki.find(".tweet")
Enum.map(tweet_html, fn(x) -> parse_tweet(x) end)
endOur parse methods take in :html or :json to differentiate them. The format of the JSON response is very similar to the HTML response, the big difference being that the HTML for the tweets is contained in the items_html field of the reponse. So all we need to do is parse out that field and then pass it along to our existing parse_tweet function.
We should now have a passing test.
Terminal
mix test
If we go into iex we’ll see our second page of tweets being parsed.
Terminal
iex -S mixTerminal
TwitterFeed.get_tweets("lolagil", 948759471467118592)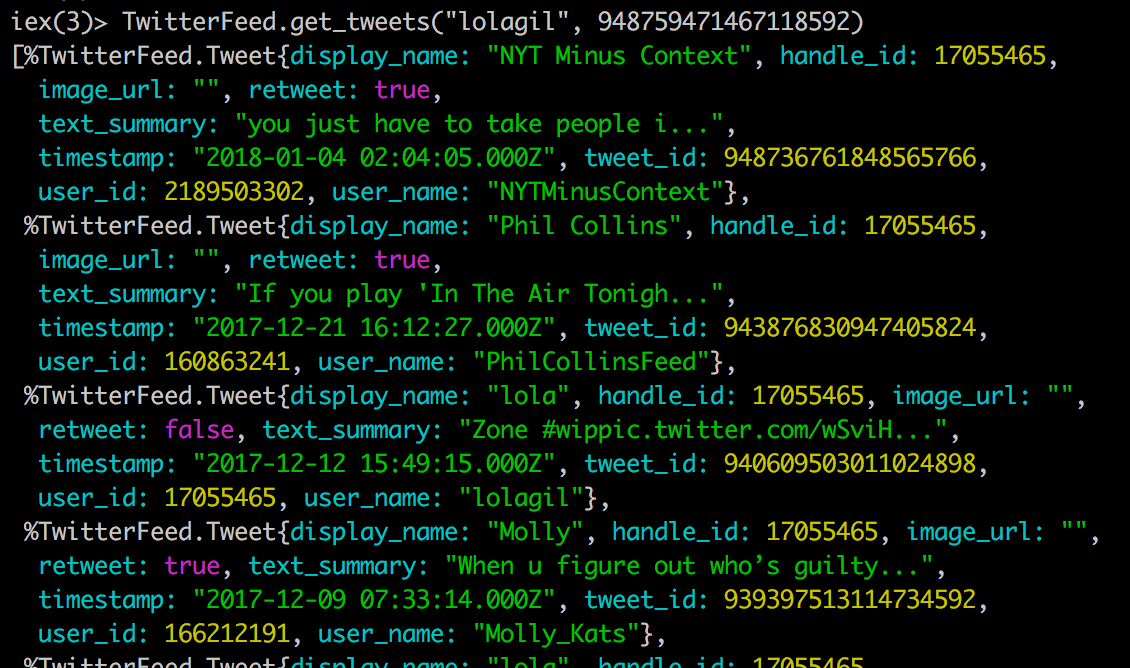
Summary
So with that, we’ve figured out how to grab subsequent pages of tweets. Next time we’ll update the information we are returning to make it easy for applications that are consuming our code to know whether more tweets exist and how to get them.
Thanks for reading and I hope you enjoyed the post!