Last time out, we managed to get a Docker image of our application building on GitLab. Today we’ll look at deploying that image via GitLab’s Kubernetes integration.
Getting started
If you’ve been following along you can continue with the code from part 2 or you can clone the code.
Clone the Repo:
If cloning:
Terminal
git clone -b 3-add-docker-build git@gitlab.com:riebeekn/phx_gitlab_ci_cd.gitNote: if cloning, you’ll need to run deps.get and npm install after grabbing the code.
Create a branch
Now let’s create a branch for today’s work.
Terminal
cd phx_gitlab_ci_cd
git checkout -b 4-add-deploymentsSetting up our infrastructure
Much of today’s post is going to be outside of our code base and involve setting up the infrastructure pieces required to get the deployments going. We’ll be using Digital Ocean, so you’ll need an account on Digital Ocean, and be aware you will acquire some Digital Ocean fees (albeit minor) by following along with today’s post. Make sure to destroy your resources afterwards to avoid continued charges!
As a final note before we get going… we should probably be using Terraform or another “infrastructure as code solution” to provision our resources, but the Digital Ocean set-up is pretty simple so I decided instead of adding yet another tool to this series of posts I’d stick with a manual set up.
Creating the Kubernetes cluster
The first piece of infrastructure is our Kubernetes cluster.
From within Digital Ocean, select Create –> Clusters.
On the Create a cluster page, select appropriate settings; I’ve selected the region closest to me and a single node to keep costs at a minimum. I’ve also specified a cluster name, but leaving the default is fine as well.
Note: as pointed out by a reader in the comments; Digital Ocean currently uses Kubernetes 1.16 by default which is not compatible with GitLab at the moment. So you’ll need to select 1.15 as your Kubernetes version when creating the cluster.
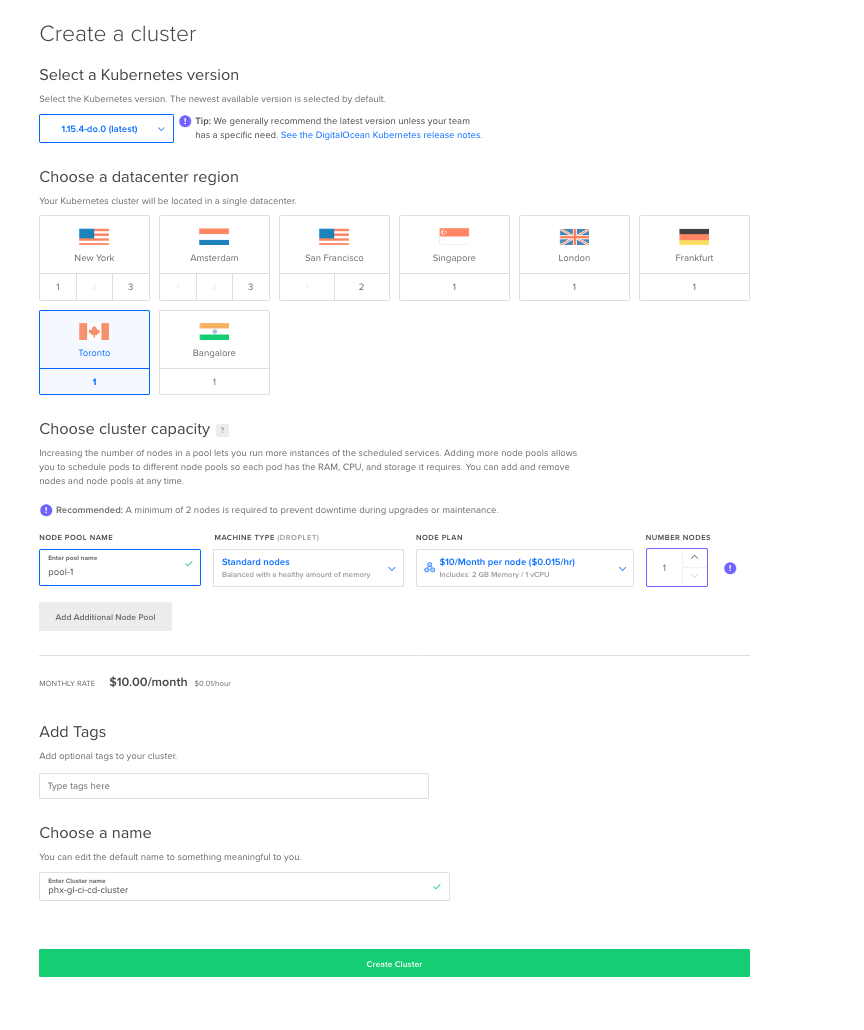
After filling in the form click Create Cluster. A Getting Started dialog will appear, ignore this for now, just wait for the cluster to be created. Now it is time to create the Database.
Creating the Database cluster
From within Digital Ocean, select Create –> Databases.
On the Create a database cluster page, select PostgreSQL as the engine and an appropriate region. Optionally you can rename the cluster (I kept the default).
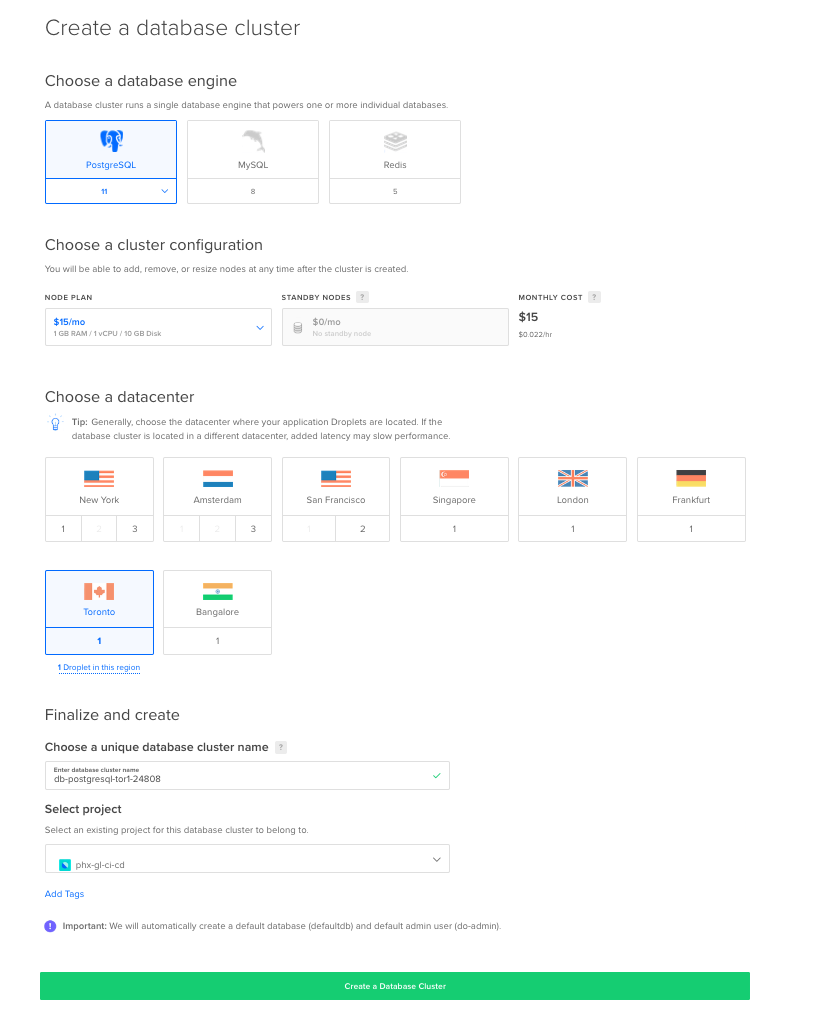
After the cluster has been created, navigate to the Users & Databases tab. We need to add a user and database for our application.
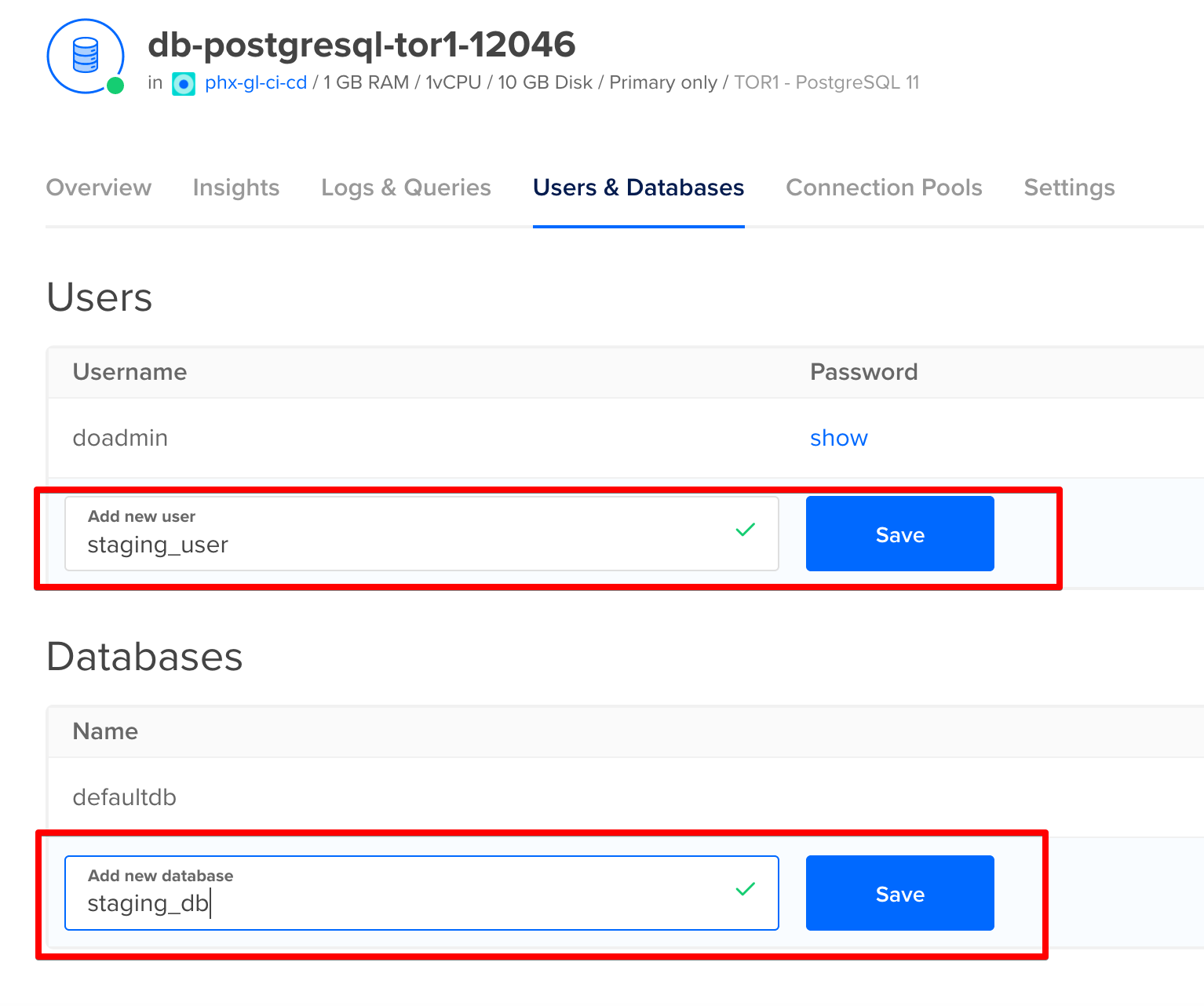
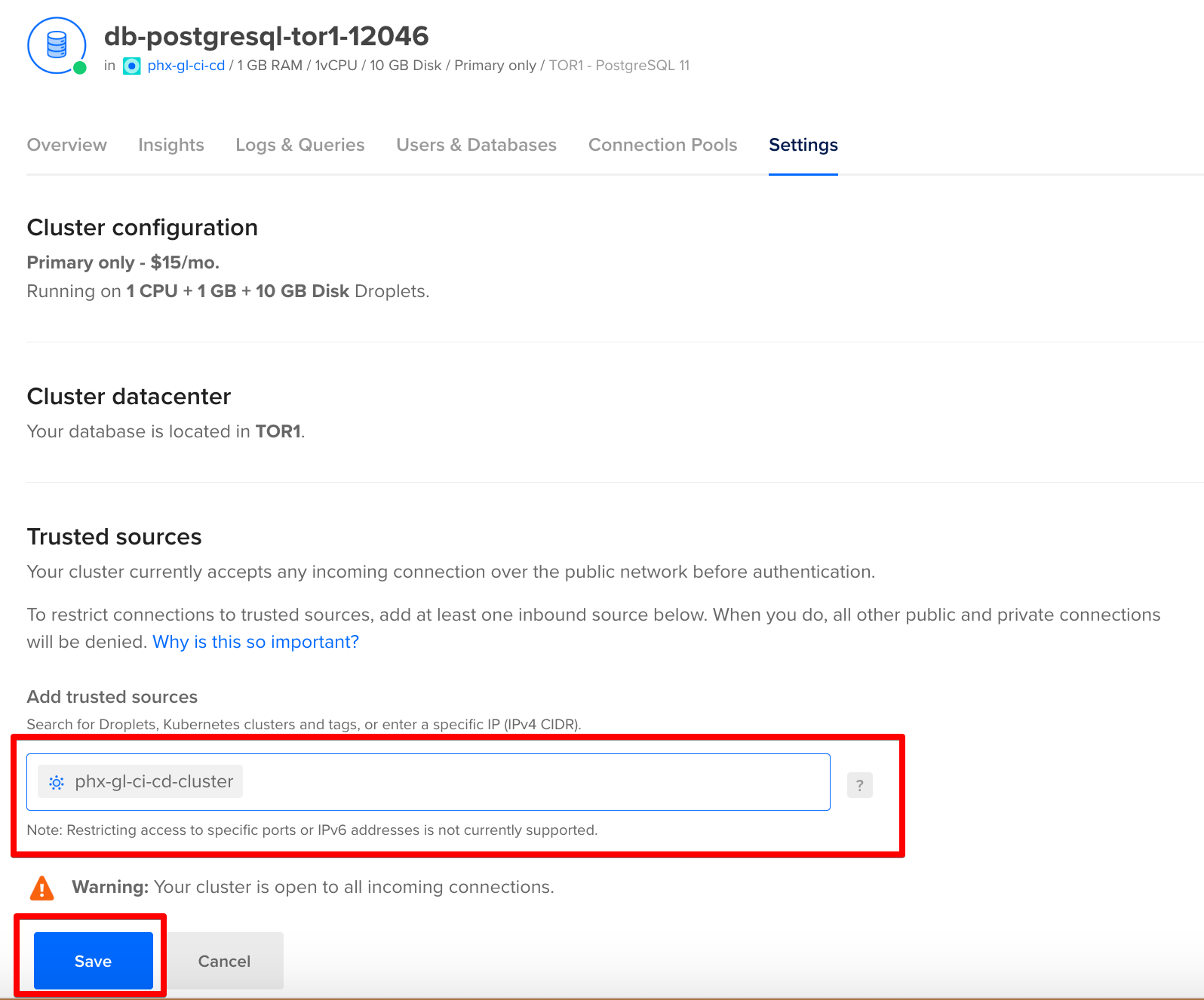
Now move over to the Settings tab and lock down access to the database by adding our Kubernetes cluster as a trusted source.
Accessing our Kubernetes cluster
Finally we need to be able to access our Kubernetes cluster.
To do so we first need to install doctl, if you’re on a Mac, the easiest approach is likely Homebrew (brew install doctl).
Once installed, we can then use doctl to download and save the configuration file for the cluster. See here for more information if you’re curious about what you can do with doctl.
Terminal
doctl kubernetes cluster kubeconfig save phx-gl-ci-cd-cluster
And with that, we are ready to integrate with GitLab.
Integrating the cluster with GitLab
First off we’ll need to have kubectl installed, again if on a Mac, Homebrew (brew install kubernetes-cli) is likely the easiest option.
Once kubectl is installed, we’re ready to go.
Login to GitLab and navigate to Operations –> Kubernetes.
Click Add Kubernetes cluster and then select the Add existing cluster tab.
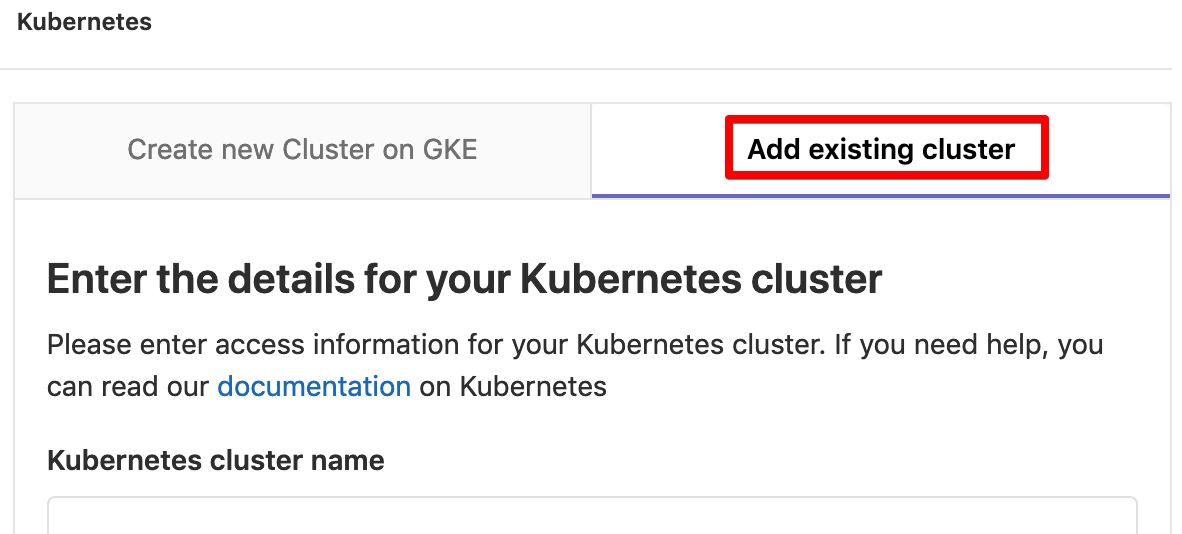
Let’s fill in the form fields one by one:
Kubernetes cluster name
I’ll use phx-gl-ci-cd-cluster to match the cluster name in Digital Ocean, but this isn’t necessary, you can use any name you want and the Digital Ocean and GitLab names do not need to match.
API URL
This is URL of our Digital Ocean Kubernetes cluster. We can retrieve this via:
Terminal
kubectl cluster-info | grep 'Kubernetes master' | awk '/http/ {print $NF}'
CA Certificate
We need to retrieve the certificate from the Digital Ocean cluster. First retrieve the default-token value.
Terminal
kubectl get secrets
Now run the below, replacing the default-token value with the value from above.
Terminal
kubectl get secret default-token-4vwx6 -o jsonpath="{['data']['ca\.crt']}" | base64 --decode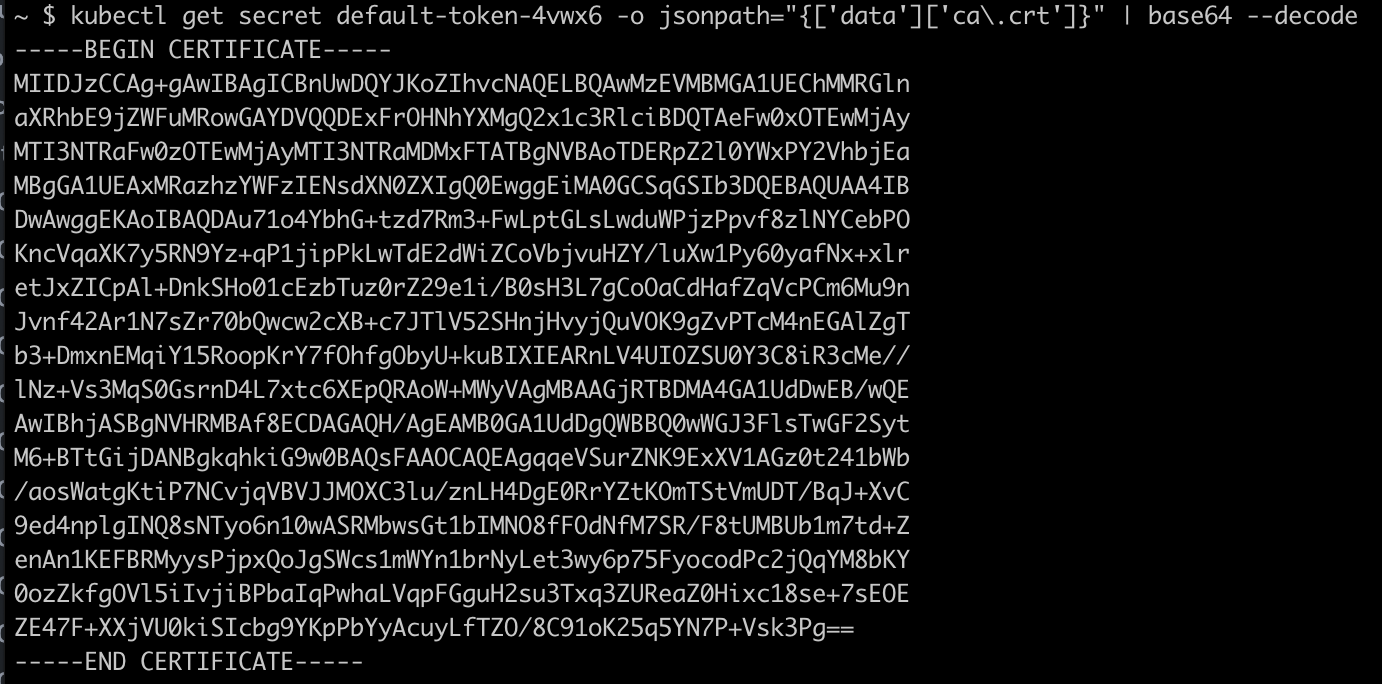
Enter the full certificate including the BEGIN / END lines.
Service Token
Create the following file outside of the project directory (or delete it after, as we don’t need it in source control):
Terminal
touch gitlab-admin-service-account.yamlgitlab-admin-service-account.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gitlab-admin
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: gitlab-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: gitlab-admin
namespace: kube-systemNow apply the service account specified in the file to the cluster:
Terminal
kubectl apply -f gitlab-admin-service-account.yaml
Finally retrieve the service token value.
Terminal
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep gitlab-admin | awk '{print $1}')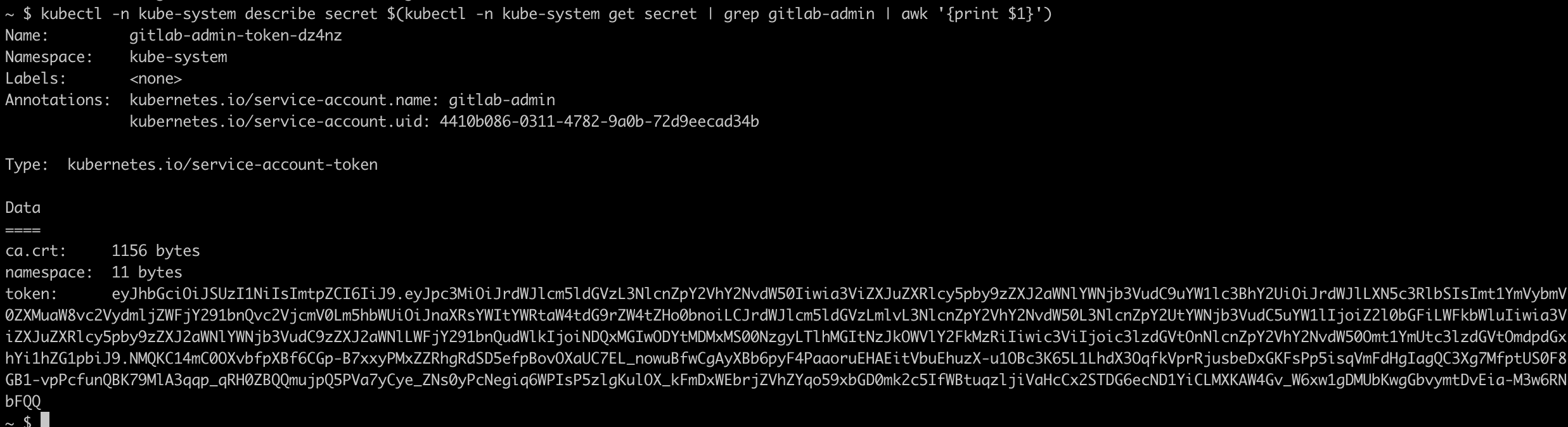
The other fields we can leave as is.
The form should now look something like:
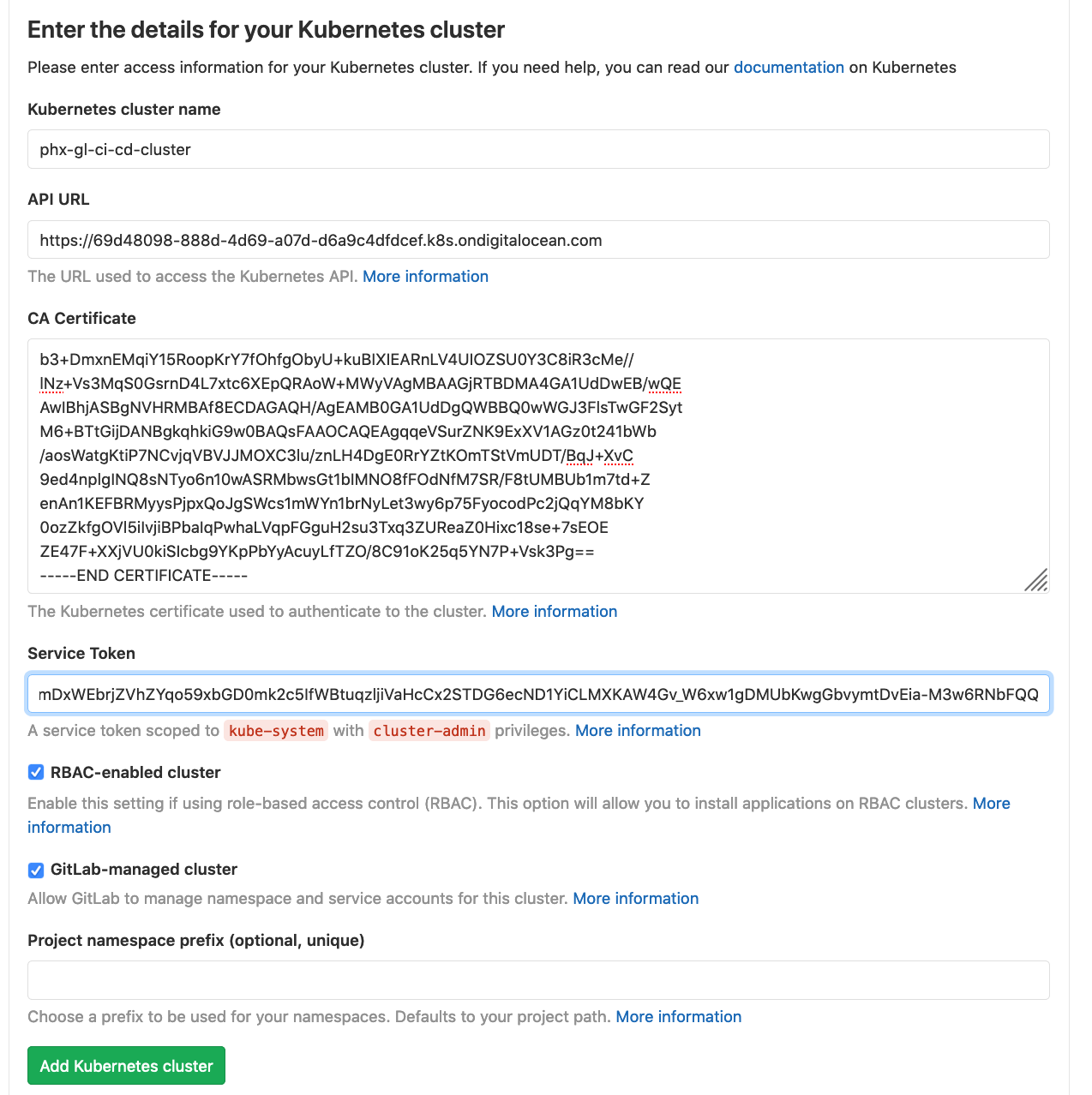
Click Add Kubernetes cluster.
You will now be presented with the cluster page:
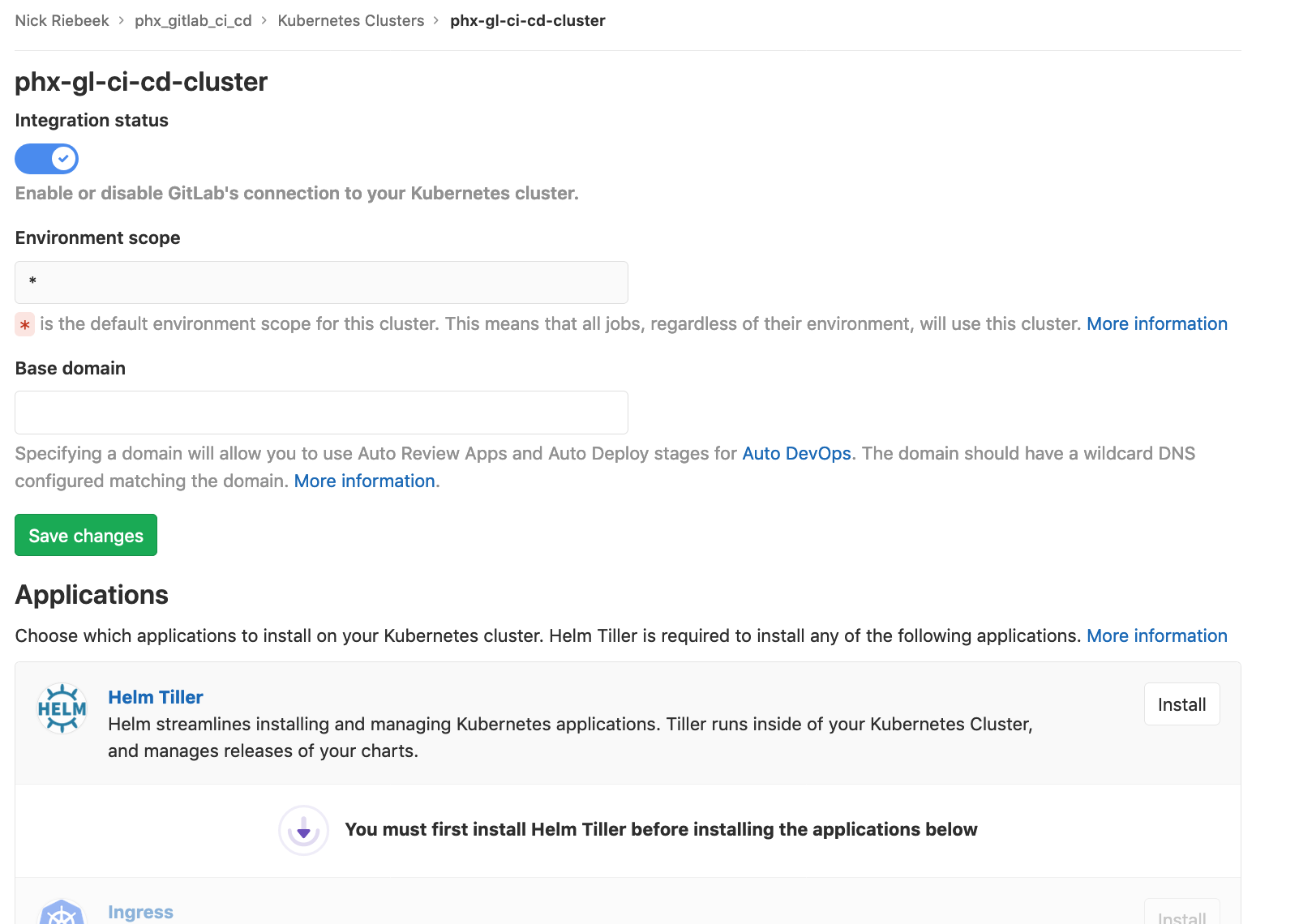
Install Helm Tiller and once that completes install Ingress.
After Ingress has installed set the Base domain based on the Ingress Endpoint, and click Save changes.
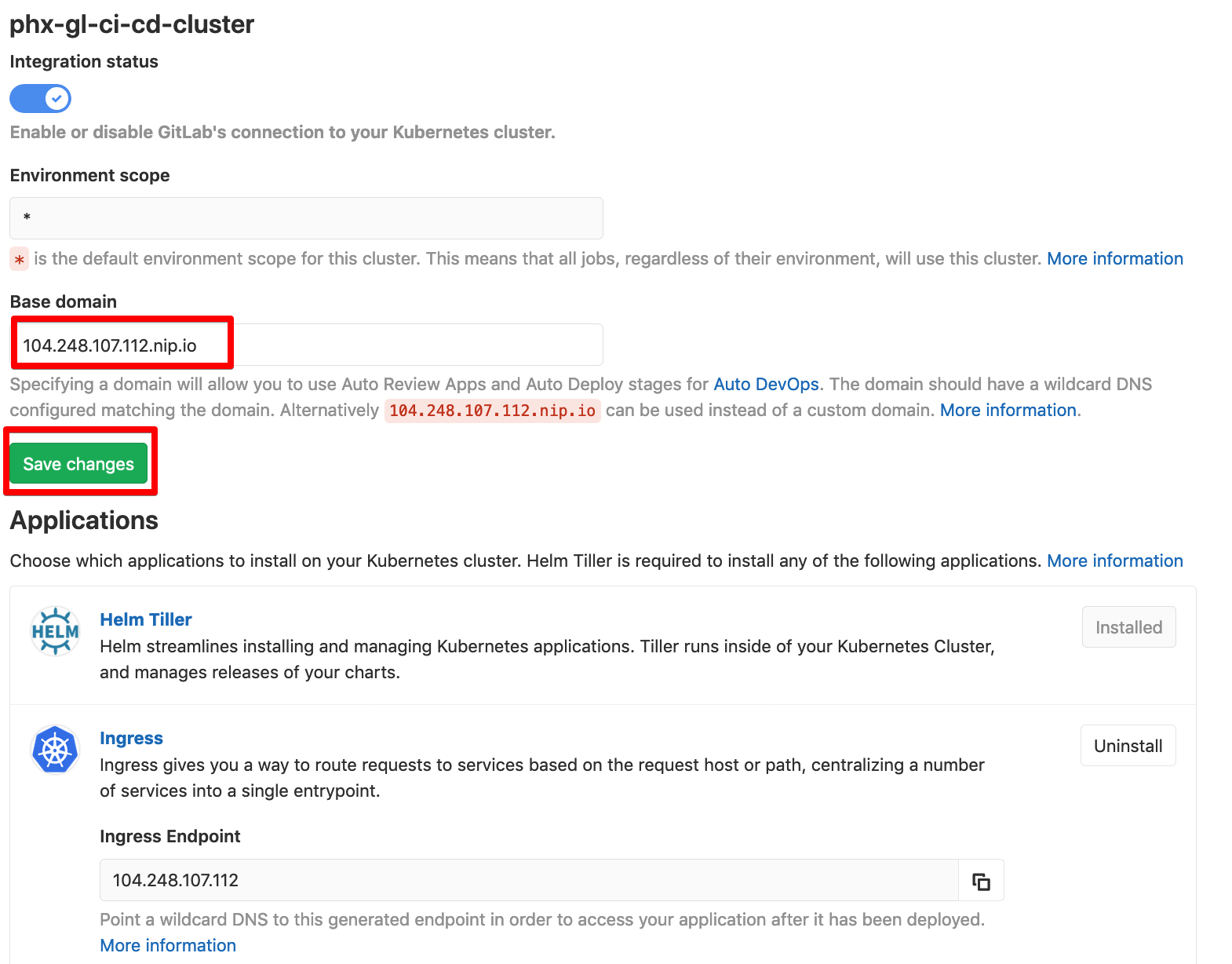
Finally install Cert-Manager.
That’s it, we are done integrating, time to add a deployment to our pipeline!
Creating a Staging deployment
Back over in our code, the first step is to update the gitlab-ci.yml file.
/.gitlab-ci.yml
# Main CI yml file for GitLab
stages:
- build
- test
- docker
- staging
# reference to the GL auto-deploy image
.auto-deploy:
image: "registry.gitlab.com/gitlab-org/cluster-integration/auto-deploy-image:v0.1.0"
include:
- local: "/ci/build.yml"
- local: "/ci/test.yml"
- local: "/ci/build-docker.yml"
- local: "/ci/deploy-staging.yml"We’ve added a new stage and local reference, in addition to a reference to the GitLab auto-deploy image. This image will be used in our deployment stages. Since we anticipate we’ll have more than just a staging deployment, i.e. we’ll also have a production deployment, we’ll define the reference in our main file instead of duplicating it in each deployment file.
Time to create the deploy-staging file.
Terminal
touch ci/deploy-staging.yml/ci/deploy-staging.yml
staging:
extends: .auto-deploy
stage: staging
cache: {}
# variables pre-pended with "K8S_SECRET_" will be made available within the
# K8S / Docker container. The prefix will be stripped, i.e. within the
# container "K8S_SECRET_DB_HOST" is referenced with "DB_HOST"
# The "STAGING" variables being assigned below are defined in the
# GitLab UI (Setting --> CI / CD --> Variables)
variables:
POSTGRES_ENABLED: "false"
K8S_SECRET_PORT: "5000"
K8S_SECRET_SECRET_KEY_BASE: $STAGING_SECRET_KEY_BASE
K8S_SECRET_DB_HOST: $STAGING_DB_HOST
K8S_SECRET_DB_INSTANCE: $STAGING_DB_INSTANCE
K8S_SECRET_DB_USER: $STAGING_DB_USER
K8S_SECRET_DB_PASSWORD: $STAGING_DB_PASSWORD
K8S_SECRET_DB_PORT: $STAGING_DB_PORT
ROLLOUT_RESOURCE_TYPE: deployment
before_script: []
script:
- auto-deploy check_kube_domain
- auto-deploy download_chart
- auto-deploy ensure_namespace
- auto-deploy initialize_tiller
- auto-deploy create_secret
- auto-deploy deploy
# requires manual triggering
# when: manual
environment:
name: staging
url: http://$CI_PROJECT_PATH_SLUG-staging.$KUBE_INGRESS_BASE_DOMAINThe above is largely sourced from the GitLab Auto-DevOps yaml file. The main thing to be aware of is the variables section. As per the comments, the variables pre-pended with K8S_SECRET will be passed to our container. This is how we specify the values required by our Docker image. In theory we could hard-code these values (and I’ve done so above with the K8S_SECRET_PORT variable), but we don’t want to have to change our scripts to alter these values (for instance if for some reason our database host changes). Also some of these values are sensitive so we wouldn’t want to check them into source control. As a result we’re using variables to set the variables (lol)… and GitLab has us covered as to how to handle this.
Adding environment specific variables
Back in GitLab, navigate to Settings –> CI/CD.
We need to add variables for the 6 dynamic variables in the deploy-staging.yml file. Once done we should have something that looks like:
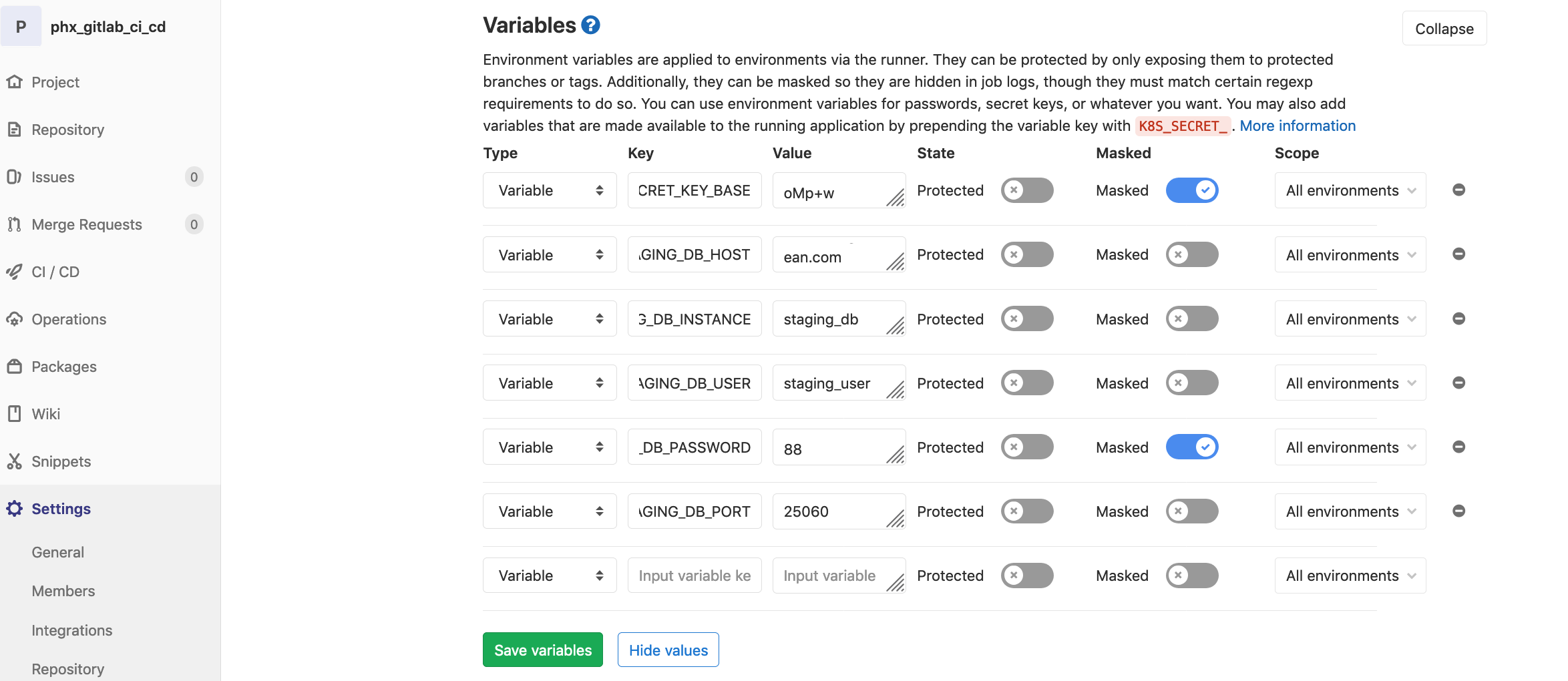
The values for our variables are:
STAGING_SECRET_KEY_BASE
We can generate this via:
Terminal
mix phx.gen.secretEverything else we can get from the Digital Ocean database cluster.
We can grab the STAGING_DB_HOST and STAGING_DB_PORT values from the overview section.
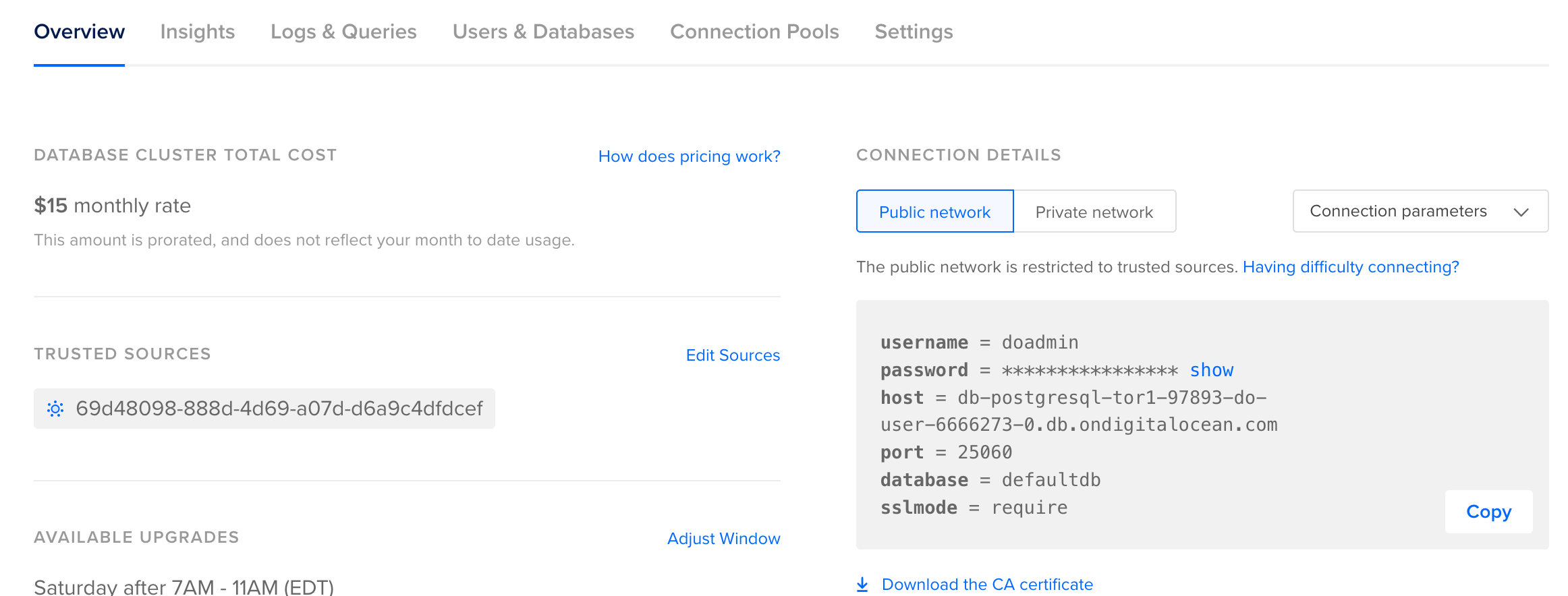
Then we can grab the STAGING_DB_INSTANCE, STAGING_DB_USER and STAGING_DB_PASSWORD values from the users and databases section.
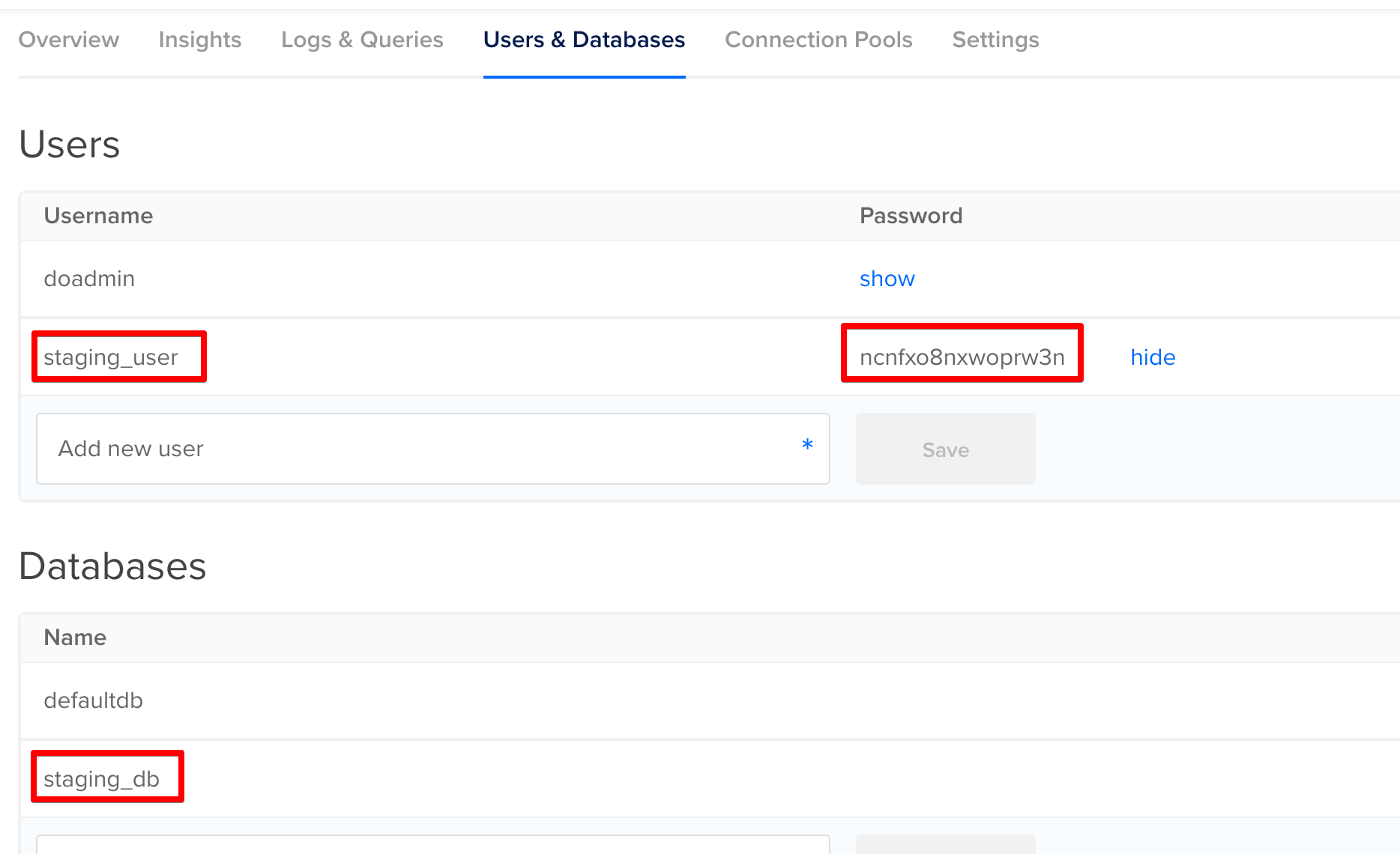
With our new yaml files and the variables in place, we should be good to go… let’s give it a try.
Terminal
git add .
git commit -am "Add staging deploy stage"
git push origin 4-add-deploymentsWe should see a new stage and job in our pipeline:
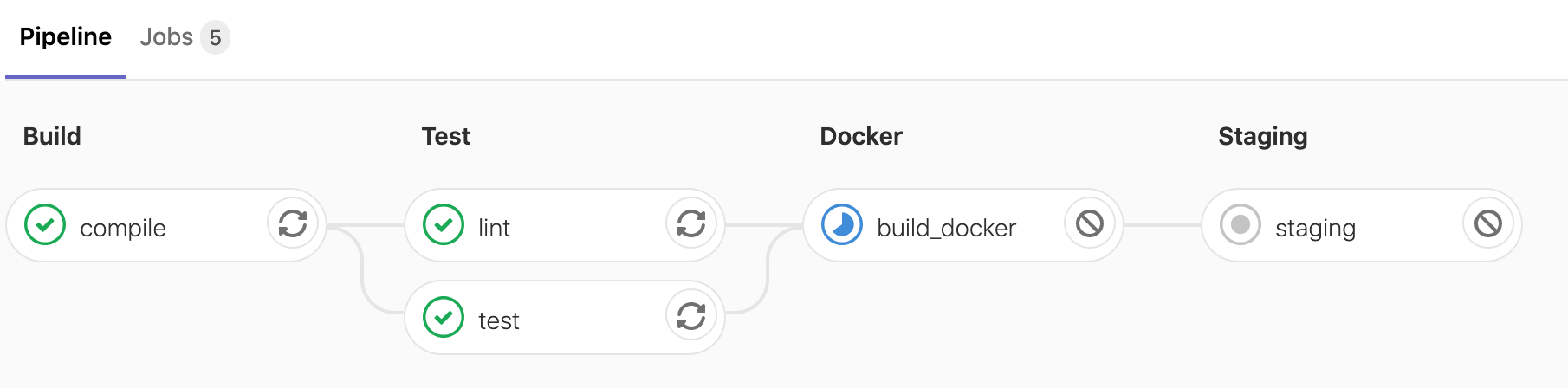
And after a few minutes our jobs should all succeed:
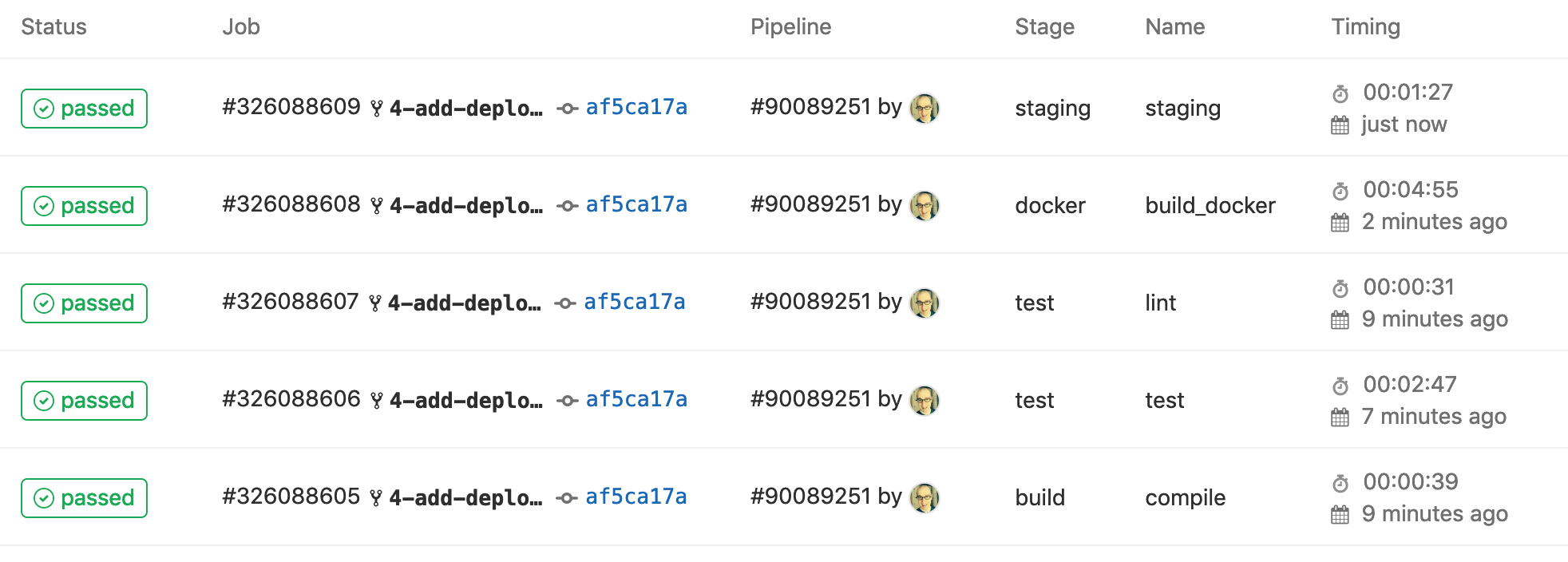
Click on the job number of the staging job to see the details of the job. From the details we can get the URL of our staging deployment.
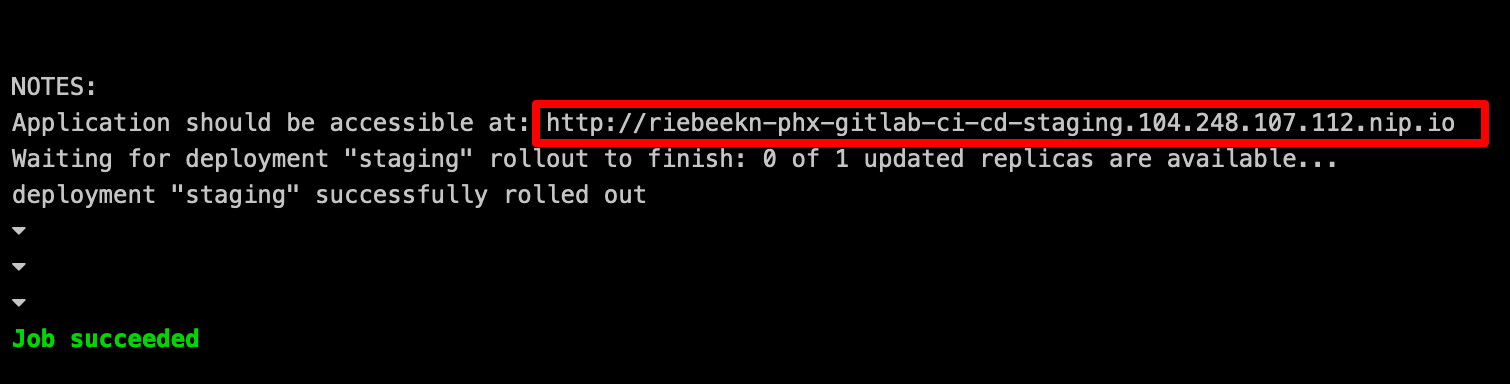
Let’s check it out:

Sweet!
Creating a Production deployment
We can now follow similar steps to create a production deployment.
Note: with a real application you might want to create a separate Kubernetes cluster for your different environments. This can be done in GitLab (Multiple Kubernetes clusters), but requires a premium account so we’re sticking with a single cluster.
Let’s add a new stage to the main .yml file.
/.gitlab-ci.yml
# Main CI yml file for GitLab
stages:
- build
- test
- docker
- staging
- production
# reference to the GL auto-deploy image
.auto-deploy:
image: "registry.gitlab.com/gitlab-org/cluster-integration/auto-deploy-image:v0.1.0"
include:
- local: "/ci/build.yml"
- local: "/ci/test.yml"
- local: "/ci/build-docker.yml"
- local: "/ci/deploy-staging.yml"
- local: "/ci/deploy-production.yml"And then create the deploy-production.yml file.
Terminal
touch ci/deploy-production.yml/ci/deploy-production.yml
production:
extends: .auto-deploy
stage: production
cache: {}
# variables pre-pended with "K8S_SECRET_" will be made available within the
# K8S / Docker container. The prefix will be stripped, i.e. within the
# container "K8S_SECRET_DB_HOST" is referenced with "DB_HOST"
# The "PROD" variables being assigned below are defined in the
# GitLab UI (Setting --> CI / CD --> Variables)
variables:
POSTGRES_ENABLED: "false"
K8S_SECRET_PORT: "5000"
K8S_SECRET_SECRET_KEY_BASE: $PROD_SECRET_KEY_BASE
K8S_SECRET_DB_HOST: $PROD_DB_HOST
K8S_SECRET_DB_INSTANCE: $PROD_DB_INSTANCE
K8S_SECRET_DB_USER: $PROD_DB_USER
K8S_SECRET_DB_PASSWORD: $PROD_DB_PASSWORD
K8S_SECRET_DB_PORT: $PROD_DB_PORT
ROLLOUT_RESOURCE_TYPE: deployment
before_script: []
script:
- auto-deploy check_kube_domain
- auto-deploy download_chart
- auto-deploy ensure_namespace
- auto-deploy initialize_tiller
- auto-deploy create_secret
- auto-deploy deploy
- auto-deploy delete canary
- auto-deploy delete rollout
- auto-deploy persist_environment_url
# requires manual triggering
when: manual
# this stage only runs on pushes to master
only:
refs:
- master
environment:
name: production
url: http://$CI_PROJECT_PATH_SLUG.$KUBE_INGRESS_BASE_DOMAIN
artifacts:
paths: [environment_url.txt]This is almost exactly the same as deploy-staging. A few differences:
- We only run this stage on pushes to master (via
refs: master). - We’ve set a manual trigger for this stage (via
when: manual). - We’re using different variables, instead of
$STAGING_, we’re pre-pending our variables with$PRODUCTION_.
We of course are going to need to create the production variables in GitLab as we did for the staging variables. And we also want to set up a production database instance, user and password on our Digital Ocean database cluster.
I’m not going to provide a walk-thru of the above as we’ve already done so when setting up staging.
However, once the new database and variables are in place, we can give it a go.
Terminal
git add .
git commit -am "Add staging deploy stage"
git push origin 4-add-deploymentsIf we have a look at our pipeline, the production stage is not showing up. 😖… what is going on?
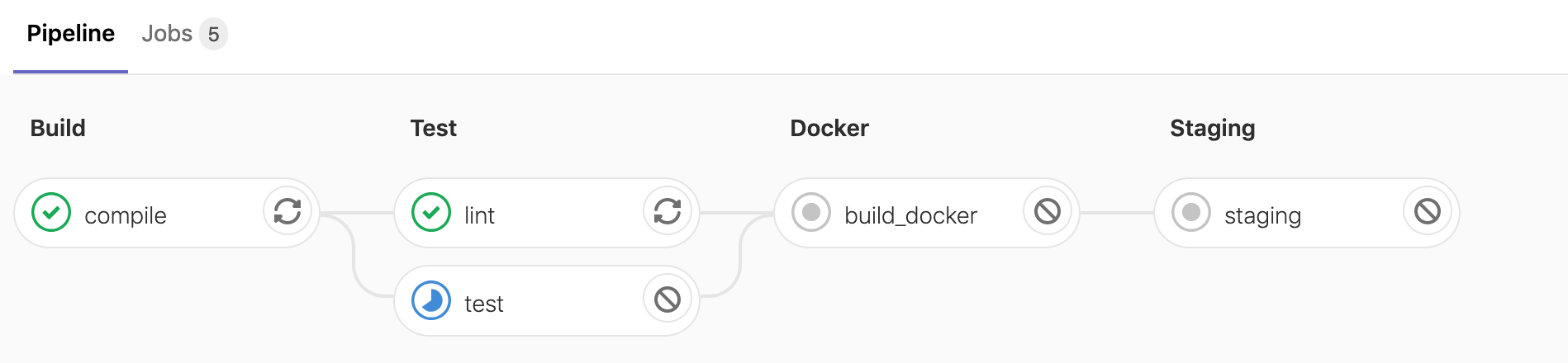
This is actually the expected behaviour, remember we specified that the production stage should only run on check-ins to master.
So let’s merge our code into our master branch.
Terminal
git checkout master
git merge 4-add-deploymentsWhen prompted for a merge comment you can leave it as is.

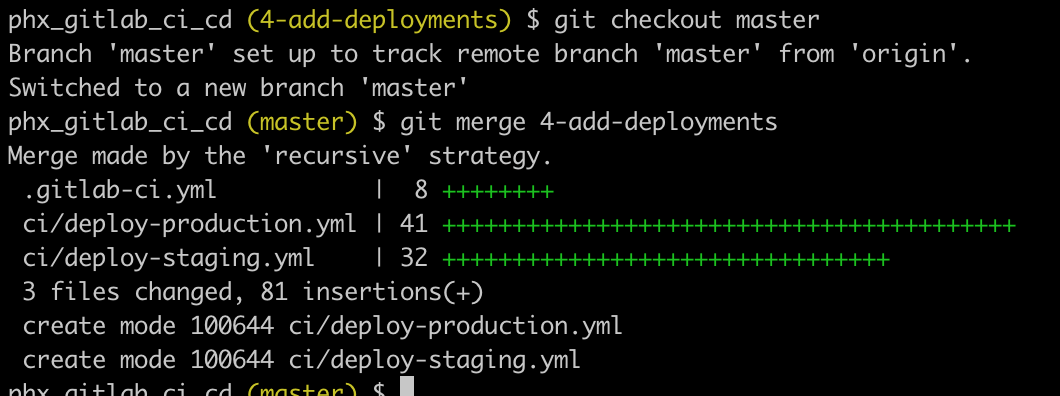
And now we can push to master.
Terminal
git pushWe now see our new stage in the pipeline.

After a few minutes all our jobs will complete, but notice the production job doesn’t run automatically.
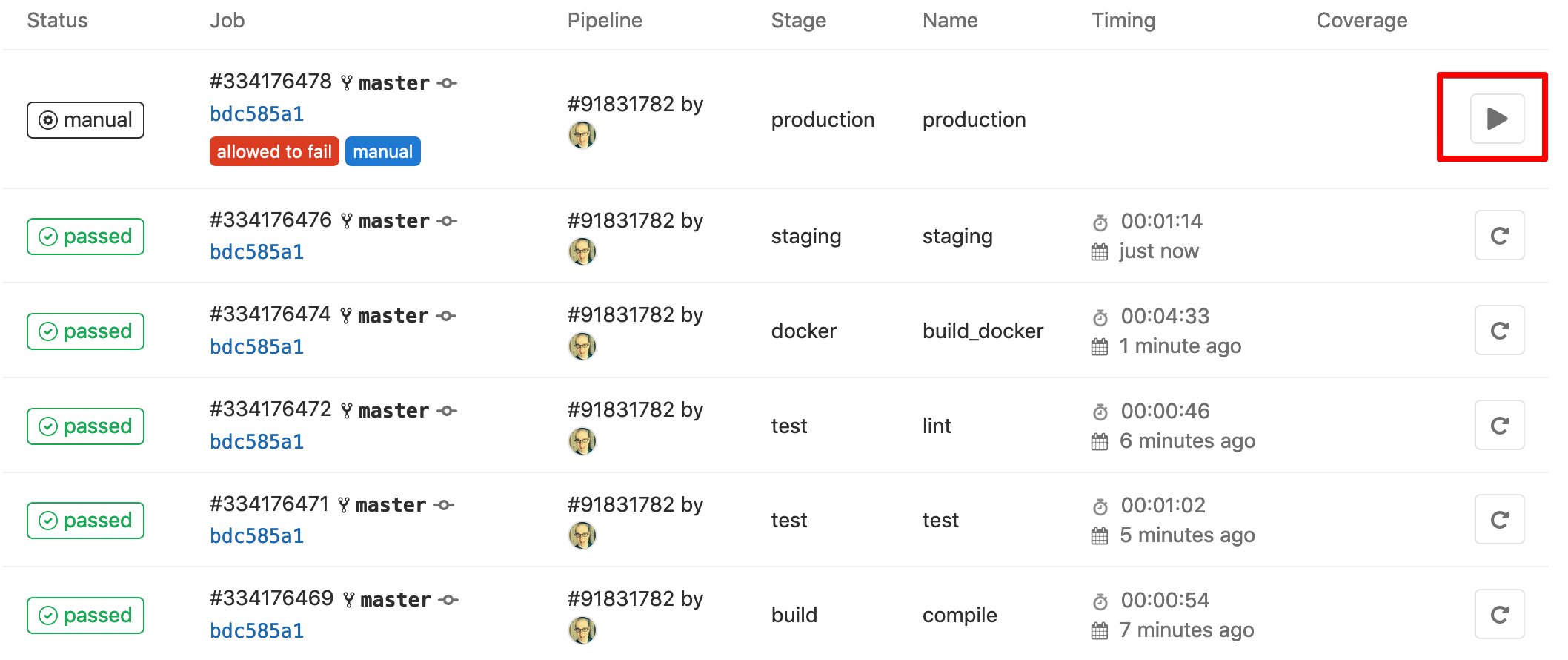
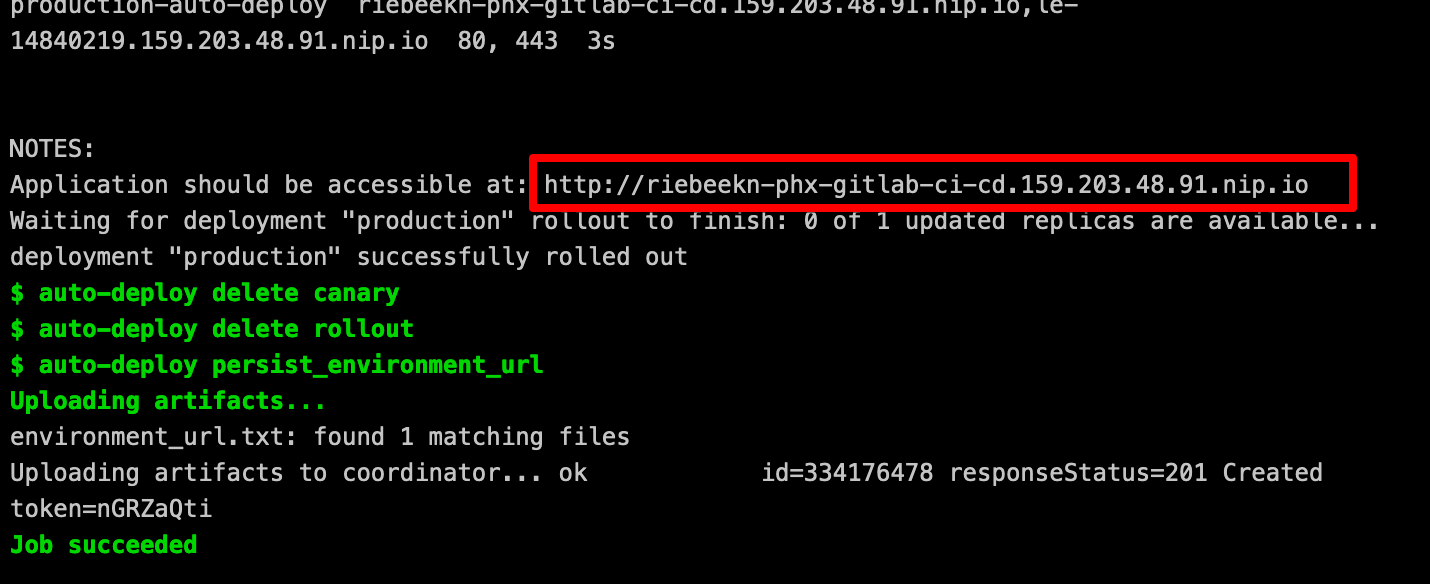
Since we set this job to manual, we need to… you guessed it, manually run it. After doing so we have a new “production” environment deployed.
Summary
So that’s it for this series of posts on GitLab. We’ve got a pretty good system set-up that allows us to test, build and deploy our code with relative ease.
There are still a number of really cool features that I haven’t touched on such as review apps and visual reviews. Possibly I’ll do a write up of these if / when I become more familiar with them.
Thanks for reading, hope you enjoyed the post!