In Part 1 we created our basic project structure and added code to build the URLs to retrieve data from Twitter. In this post we’ll get started on actually doing the data retrieval.
I’d encourage you to follow along, but if you want to skip directly to the code, it’s available on GitHub at: https://github.com/riebeekn/elixir-twitter-scraper.
Getting started
If you followed along with part 1 just continue on with the code you created in part 1. If not and you’d rather jump right into part 2, you can use a clone of part 1 as a starting point.
Clone the Repo
If grabbing the code from GitHub instead of continuing along from part 1, the first step is to clone the repo.
Terminal
git clone -b part-01 https://github.com/riebeekn/elixir-twitter-scraper twitter_feed
cd twitter_feedWhat we’re starting with
OK, you’ve either gotten the code from GitHub or are using the existing code you created in Part 1, let’s see where we’re starting from.
Terminal
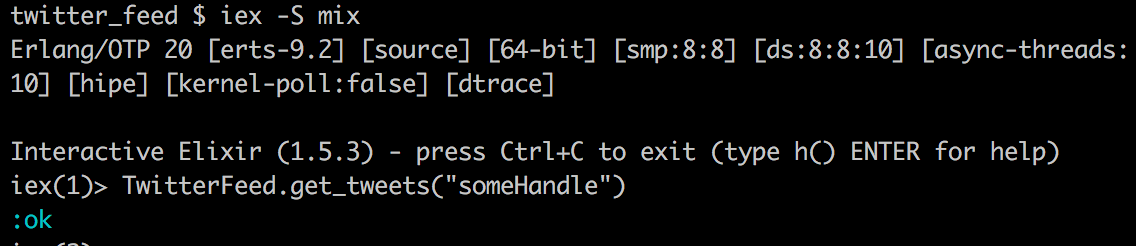
iex -S mixAfter iex loads we can run our get_tweets function that we created in part 1.
Terminal
TwitterFeed.get_tweets("someHandle")As of now it just returns an :ok atom.
Let’s figure out how to retrieve some actual data.
Retrieving data
For now we’re going to concentrate on retrieving the first page of tweets for a particular user. If you recall, this involves going to the main Twitter page for the user; for now we won’t worry about making the JSON requests needed for grabbing subsequent pages of data. We’ll be using HTTPoison to retrieve our data, so let’s add the package to our project.
Add HTTPoison
Update the deps section of mix.exs to include HTTPoison.
/mix.exs
defp deps do
[
{:excoveralls, "~> 0.8", only: :test},
{:httpoison, "~> 1.0"}
]
endAnd now we need to update our dependencies:
Terminal
mix deps.get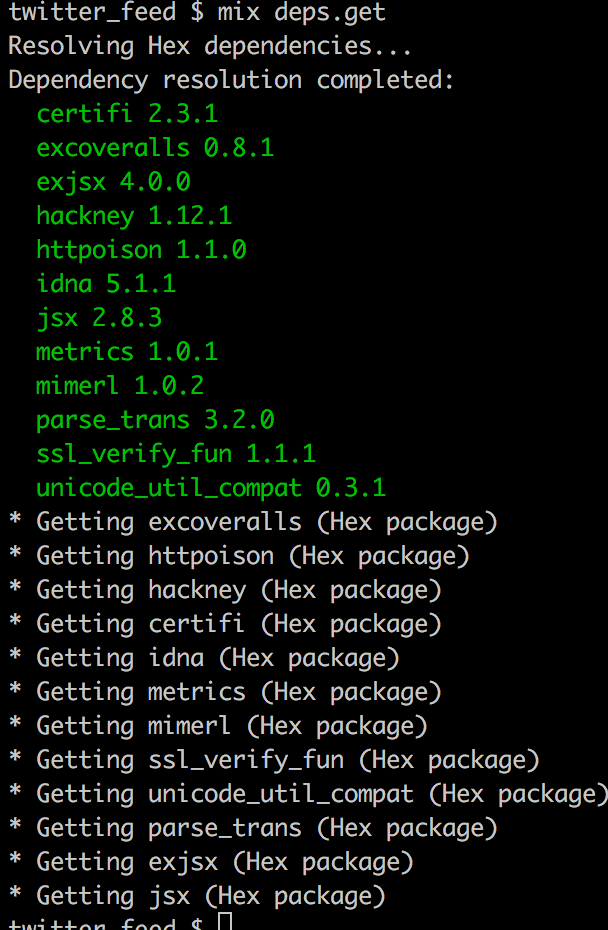
Sweet, we’re good to go!
Retrieving the first page of Tweets
We’ll create a new module in our twitter_api directory for handling HTTP requests, we’ll call it http_client.
Terminal
touch lib/twitter_feed/twitter_api/http_client.ex/lib/twitter_feed/twitter_api/http_client.ex
defmodule TwitterFeed.TwitterApi.HttpClient do
@moduledoc false
alias TwitterFeed.TwitterApi.UrlBuilder
def get_home_page(handle) do
UrlBuilder.build_html_url(handle)
|> HTTPoison.get()
end
endNothing complicated going on here, we’re using the UrlBuilder module we created earlier to build the appropriate URL, and then passing that off to HTTPoison.
Let’s update scraper.ex to make use of our new module.
/lib/twitter_feed/scraper.ex
defmodule TwitterFeed.Scraper do
@moduledoc false
alias TwitterFeed.TwitterApi.HttpClient
def scrape(handle, _start_after_tweet) do
handle
|> HttpClient.get_home_page()
end
endNotice we’ve removed the underscore from the handle parameter and we’re passing it into the HttpClient call that we’ve added.
Now restart iex (we need to restart it since we added a new dependency) and let’s see if we are retrieving data.
Terminal
iex -S mixTerminal
TwitterFeed.get_tweets("lolagil")If you look carefully at the response we get back, you’ll notice there are two pieces of information being returned to us:
-
An
:okatom.
-
A response structure that itself contains a number of elements.
- A body section

- A headers section
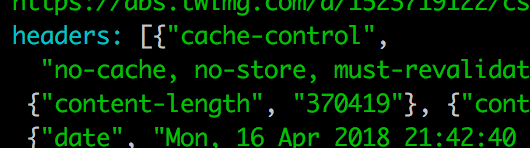
- A request_url and status_code

- A body section
With this in mind, let’s update our scraper code slightly.
/lib/twitter_feed/scraper.ex
defmodule TwitterFeed.Scraper do
@moduledoc false
alias TwitterFeed.TwitterApi.HttpClient
def scrape(handle, _start_after_tweet) do
case HttpClient.get_home_page(handle) do
{:ok, %{status_code: 200, body: body}} ->
body
{:ok, %{status_code: 404}} ->
return_404()
end
end
defp return_404 do
{:error, "404 error, that handle does not exist"}
end
endWe’re using a case statement and some pattern matching to return the body on a 200 response, in the case of a 404 response we return an error.
Let’s recompile and run our function again in iex.
Terminal
recompile;TwitterFeed.get_tweets("lolagil")We now have our body returning in the case where the handle is found:

And as expected we get an error back with an invalid handle:
Terminal
TwitterFeed.get_tweets("somehandlethatdoesnotexist")
What about testing?
Running things from iex is all well and good; it isn’t the way we want to build out our code going forward however. We want to be able to validate the functionality of our code via tests, not by typing things into the console.
We’re pretty much ok not testing the HttpClient module as it doesn’t really do anything other than call off into UrlBuilder and HTTPoison. The Scraper module however already has some logic in it and will continue to grow. So let’s create some tests for Scraper.
Terminal
touch test/twitter_feed/scraper_test.exs/test/twitter_feed/scraper_test.exs
defmodule TwitterFeed.ScraperTest do
use ExUnit.Case, async: true
alias TwitterFeed.{ Scraper }
test "scraping on non-existant handle will return 404" do
{:error, reason} = Scraper.scrape(:non_existant_handle, 0)
assert reason =~ "404 error, that handle does not exist"
end
test "scraping on valid handle will return some body content" do
body = Scraper.scrape("lolagil", 0)
assert body =~ "<!DOCTYPE html>"
end
endSo we’re testing both valid and invalid handles, checking the reason field when an invalid handle is passed in, and the body when a valid handle is passed in.
If you run mix test our tests pass…
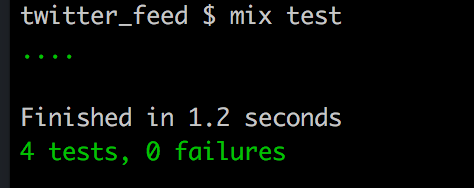
We have a few issues with our Scraper tests however.
- They rely on an external resource (Twitter).
- Our valid handle test is not really testing for much of anything.
Let’s see how we can remove our dependence on Twitter when it comes to our testing. We’ll deal with creating a better valid handle test in a future post.
Mocking out our Twitter interaction
José Valim wrote a great article on using Mocks in Elixir, it even happens to use Twitter as an example! We’ll use the technique explained in José’s article in our code.
We’ll be creating a test specific implementation of HttpClient that returns known values. Depending on whether we are running under a test or non-test environment the Scraper module will either call into the test or concrete implementation of our code.
The process for getting this all set up is:
- Create an API that both our concrete and test implementations will implement, we’ll use an Elixir
callbackfor this. - Update our existing
HttpClientmodule to make use of thecallback. - Create a test implementation of the
callback. - Add some configuration that will direct us to the test or concrete version of
HttpClientand updateScraperto use the API instead of directly calling intoHttpClient.
Yikes! I know that sounds a little involved, but it isn’t too bad and will be worth it in the long run, so let’s get going!
The first step is to define an API that HttpClient and our mock will implement.
Terminal
touch lib/twitter_feed/twitter_api/api.ex/lib/twitter_feed/twitter_api/api.ex
defmodule TwitterFeed.TwitterApi.Api do
@moduledoc false
@callback get_home_page(handle :: String.t) :: String.t
endAll this does is indicate the function(s) we want to define in both our concrete and mocked implementation. For now, the only function we need is get_home_page.
Let’s update HttpClient to make use of the API.
/lib/twitter_feed/twitter_api/http_client.ex
defmodule TwitterFeed.TwitterApi.HttpClient do
@moduledoc false
@behaviour TwitterFeed.TwitterApi.Api
alias TwitterFeed.TwitterApi.UrlBuilder
...
...Simple! We just need to add a behaviour line to HttpClient. This indicates it implements the behaviour specified in our API, and since we already have a get_home_page function in HttpClient, we’re all good to go.
Next we need to create our Mock. Let’s place it in a specific directory we’ll use for mocks.
Terminal
mkdir test/mocks
touch test/mocks/twitter_api_mock.ex/test/mocks/twitter_api_mock.ex
defmodule TwitterFeed.Mocks.TwitterApiMock do
@behaviour TwitterFeed.TwitterApi.Api
def get_home_page(:non_existant_handle) do
{:ok, %{status_code: 404}}
end
def get_home_page(_handle) do
{:ok, %{status_code: 200, body: "This handle looks good!"}}
end
endSo our mock also uses the behaviour we defined in the API, but this time we are explicitly setting the return values of our get_home_page function. A call to get_home_page with a handle of :non_existant_handle is going to return the 404 status that we get from Twitter when the real version of HttpClient attempts to grab data for an invalid handle. For any other handle we’re going to return a status of 200 and some body text.
In order to use our mock we need to reference it in the test_helper.exs file.
/test/test_helper.exs
ExUnit.start()
Code.require_file("test/mocks/twitter_api_mock.ex")We now want to update Scraper to make use of our API, instead of directly calling into HttpClient.
This will require a bit of configuration set-up. We’ll be updating the existing configuration file as well as adding dev, prod and test configurations.
Let’s start by creating the new files.
Terminal
touch config/dev.exs
touch config/prod.exs
touch config/test.exsNow we need to update the main config file so that it loads our newly created files based on the current environment (test, dev, or prod). Note: there’s a lot of comments in the default config.exs file, feel free to remove them as I’ve done or keep them hanging around if you wish.
/config/config.exs
use Mix.Config
import_config "#{Mix.env}.exs"Now we’ll specify whether to use the real or mock version of HttpClient in our enviroment specific configuration files.
/config/dev.exs
use Mix.Config
config :twitter_feed, :twitter_api, TwitterFeed.TwitterApi.HttpClient/config/prod.exs
use Mix.Config
config :twitter_feed, :twitter_api, TwitterFeed.TwitterApi.HttpClient/config/test.exs
use Mix.Config
config :twitter_feed, :twitter_api, TwitterFeed.Mocks.TwitterApiMockSo dev and prod both use the concrete implementation, test uses the mock.
The next step is to update Scraper to take into account these configurations.
/lib/twitter_feed/scraper.ex
defmodule TwitterFeed.Scraper do
@moduledoc false
@twitter_api Application.get_env(:twitter_feed, :twitter_api)
def scrape(handle, _start_after_tweet) do
case @twitter_api.get_home_page(handle) do
{:ok, %{status_code: 200, body: body}} ->
body
{:ok, %{status_code: 404}} ->
return_404()
end
end
...
...We’ve added a module attribute, @twitter_api, that gets assigned to our concrete or mock implementation of HttpClient based on the current environment we are running under. Notice we no longer need the HttpClient alias (i.e. alias TwitterFeed.TwitterApi.HttpClient), so have removed it.
The only other change is the case statement where instead of calling HttpClient.get_home_page we use the module attribute, i.e. @twitter_api.get_home_page.
In production and development we will use the concrete implementation, under test, the mock.
Let’s update our Scraper tests and see if they work.
/test/twitter_feed/scraper_test.exs
...
...
test "scraping on valid handle will return some body content" do
body = Scraper.scrape(:any_handle, 0)
assert body =~ "This handle looks good!"
end
endThe invalid_handle test requires no changes, we’ve just updated the valid handle test. Since the mock ignores the handle value, we can pass in anything for the handle. Then we just need to check for the text explicitly being returned from the mock.
If we run our tests, all is good.
Yet running from iex we still get the real data.
We now have a consistent way of running tests against our Scraper module going forward and our unit test coverage is looking good.
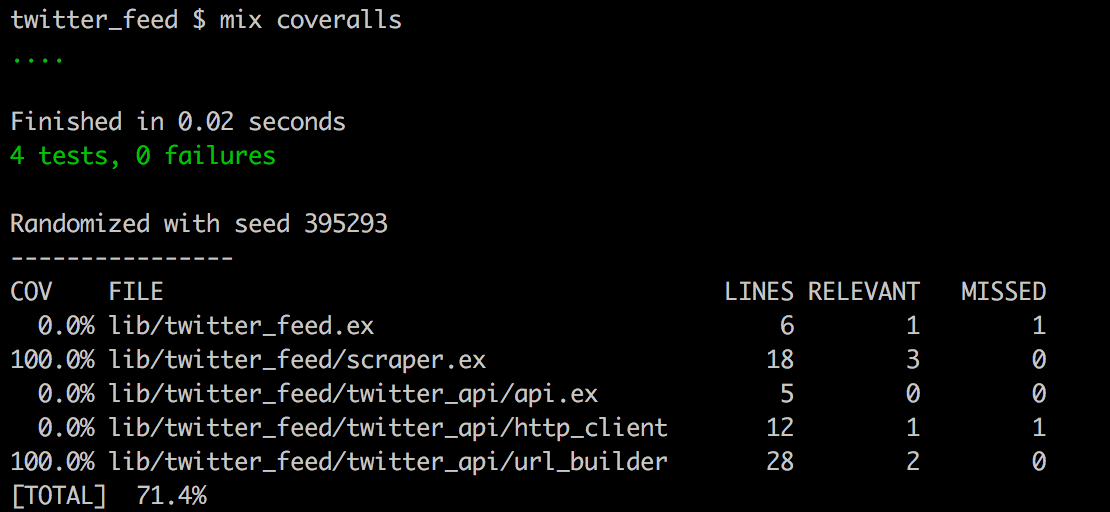
The two modules we are running tests against, Scrapper and UrlBuilder both have 100% coverage.
Summary
Similar to part 1 it seems like we accomplished more set-up than we did actual coding… but we’re now in good shape going forward. In the next post we’ll start looking into how to parse our data.
Thanks for reading and I hope you enjoyed the post!